|
Курс : "Основы С++ для начинающих программистов игр."
| |
| nilrem | Дата: Среда, 19 Августа 2009, 00:10 | Сообщение # 1 |

Просветленный разум
Сейчас нет на сайте
| Статья 1 : Первое знакомство.
1. Небольшое введение. Было ли у вас такое, что запустив свою любимую игру, вы в очередной раз вздыхали: «Вот если бы при ударе этим молотом земля вздрагивала», «Почему эта магическая стрела не проходит на вылет и не поражает следующих врагов», «А вот эту кнопочку было бы удобнее переместить сюда».
А может быть у вас уже давно есть идея сделать собственную игру, вот только вы не знаете как, с чего начать. Что ж, я попытаюсь вам в этом помочь.
Большинство тех захватывающих игр, что заставляли вас ночи напролет просиживать у монитора, написаны на языке программирования С++.
В этой и последующих статьях я познакомлю вас с основами этого замечательного языка. Сделать это я попытаюсь как можно проще и понятнее. И, поскольку мы учим С++ для того, чтобы делать игры, каждая статья будет строится на примере создания простенькой игры. Постепенно, вместе с ростом наших знаний и опыта, игры будут усложняться.
Конечно, путь этот долог и тернист, но не переживайте, у вас обязательно все получиться. Главное – не сомневаться в себе и быть настойчивым. 2. Первая программа на С++ Начнем. Думаю, что такое программа вообще, вы знаете, ну или, в крайнем случае - догадываетесь. Но что же такое программа на С++. Если не вдаваться в особые подробности то программа на С++ это никакая не программа, а текстовый документ содержащий набор необходимых инструкций, и оформленных с соблюдениями некоторых правил, которые называют синтаксисом языка. Этот текстовый документ также называют исходным текстом или исходным кодом.
Выглядит все это приблизительно так: Code #include <iostream>
using namespace std;
int main( void ) // главная функция программы
{
cout << "Начинающий программист приветствует этот мир!";
return 0;
} Совершенно непонятно, да к тому же и на английском. Правда? Ну что ж, сейчас будем со всем разбираться. Первая строчка: В мире очень много программистов. Чтобы облегчить им жизнь и сэкономить время, некоторые часто используемые фрагменты кода были собрана в обширные библиотеки. Для лучшей ориентации в этих библиотеках их содержимое описывают в специальных заголовочных файлах. Команда #include подключает один из таких файлов с названием iostream.
Следующая строчка: тесно связана с предыдущей. Она заставляет работать подключенные библиотеки так, как нам нужно. Более подробно ее назначение будет объяснено в следующих статьях, поскольку сейчас оно окажется весьма сложным.
Далее идет: Code int main( void ) // главная функция программы Первая часть строки: это название самой главной функции, с которой начинается выполнение программы. Функция - это код или фрагмент кода, выполняющий определенные действия. С ними мы также познакомимся позже. Сейчас достаточно знать, что функция с названием main должна содержаться в каждой программе.
Вторая часть строки: Code // главная функция программы это комментарий. Комментарии никак не влияют на выполнение программы. Они используются для вставки пояснений, зачем предназначен конкретный код, делая его таким образом намного понятнее.
Есть два способа писать комментарии.
Первый, тот что был использован нами в примере: (//) – использование пары слешей( слеш - это вертикальная, наклоненная вправо косая черта) . Все что находится после слешей и до конца текущей строки считается комментарием.
Второй способ – использование следующей конструкции: /*коментарий*/ /* - открывает комментарий, а */ - его закрывает. Все, что находится между ними, считается комментарием и игнорируется. Таким образом комментарий можно растянуть на несколько строк или вставить в любое место кода. Вот так: Code using namespace /*комментарий*/ std; или так: Code int main(/*комментарий*/void ) Следующая строка состоит всего из одного символа – фигурной скобки: { Эта скобка открывающая. Если посмотреть дальше по коду то можно найти ее сестру } – скобку закрывающую. Между этими скобками заключается принадлежащий функции main код. Этот код также называют «телом функции».
Но мы немного забрались вперед, поэтому возвращаемся назад к строчке: Code cout « "Здравствуй, мир!"; Здесь cout – некий объект, представляющий средство для вывода данных. Для того, чтобы им пользоваться мы и подключили файл iostream.
cout можно перевести с английского как с-Вывод(с-Out). Все что он делает в нашем случае, это печатает строку "Здравствуй, мир!" на экране. Ну и на конец: Этой строчкой заканчивается выполнение функции main. Обычно выполняющая какую либо работу функция, возвращает таким образом результат своей деятельности. Но, поскольку main у нас самая главная, и после нее уже никакие действия выполняться не будут, возвратив 0, она показывает системе, что ее работа успешно завершена.
Как вы наверное заметили, большинство строк заканчивается точкой с запятой (;). Таким образом в исходном коде эти строки отделяются друг от друга. Это обязательное правило, но не для всех строк. Чтобы понять где ставить точку с запятой, а где нет, введем такое понятие как инструкция. Каждая строчка кода, предназначенная для выполнения какого либо действия в конечной программе, называется инструкцией или оператором. По сути оператор это символ(+,-), пара символов(++, ==) или даже некий термин(sizeof), которые заставляют компьютер выполнять определенные действия. После инструкции или оператора обязательно ставится точка с запятой.
Но как мы можем видеть, после #include запятой нет. Все потому что #include - это так называемая директива предпроцессора. Директива начинаются со знака # и после нее точка с запятой не ставится. Директивы выполняются компилятором еще до начала процесса компиляции, поэтому на компиляцию поступают не они сами, а результат их работы.
Я только что трижды использовал непонятное слово – компиляция. Дальше вы узнаете, что это такое. 3. Немного о компиляции Мы уже разобрались с устройством простейшей программы на С++. Все, что теперь нужно, это увидеть как она работает. Но не все так просто. Для того чтобы запустить программу, из понятной нам ее нужно сделать понятной для нашего компьютера.
Представьте что компьютер это иностранец, с которым вам необходимо поговорить, но требуемого языка вы не знаете. В таком случае вам поможет переводчик. Вот и в компьютере используется подобный переводчик, превращающий написанный вами исходный текст в понятный компьютеру «машинный код». Это делается с помощью специальной программы - компилятора, а сам процесс называется компиляцией. Только странный это переводчик. В машинный код он переводить умеет, а вот обратно – нет.
Но компиляция не делает из исходного кода полноценную программу. Компилятор лишь выдает нам результат своей работы - объектный файл. Почему так?
В нашей программе используется средство для вывода текста в виде объекта cout, функциональность которого обеспечивается сторонней библиотекой. Для работы эта библиотека, да и другие, о которых вы пока и понятия не имеете, должна быть подключена к вашей программе. Эти функции выполняет программа компоновщик. Она запускается после компилятора и компонует(собирает вместе) ваш объектный файл с необходимыми библиотеками, в результате чего создает исполняемый файл.
Как же все сложно, скажете вы. И будете правы. Когда-то все эти действия приходилось выполнять вручную, но сейчас для этих целей созданы специальные программы, в которых все необходимые инструменты(компилятор, компоновщик, редактор исходного кода и другие) собраны(интегрированы) вместе. Они так и называются - Интегрированная среда разработки программного обеспечения. На английском - Integrated Development Environment или сокращенно – IDE. Этим нерусским термином мы и будем чаще всего пользоваться. 4. Подготовка и основы работы с IDE Microsoft Visual Studio 2008 В процессе обучения мы будем использовать среду разработки Microsoft Visual Studio 2008. Взять ее можно на официальном сайте компании Микрософт. Студия поставляется в нескольких версиях:
Express – бесплатная, но с сильно урезанной функциональностью.
Standard, Professional, Team System – платные и полнофункциональные, но Микрософт дает на них довольно продолжительный период ознакомительного(триал) использования, на некоторые версии до 180 дней. Для обучения вполне хватит.
В общем, выбор я оставляю на ваше усмотрения, но сам буду использовать Microsoft Visual Studio Team System 2008(В дальнейшем я буду называть ее просто - Студия ). Если у вас не эта версия, то возможны некоторые отличия в интерфейсе на скринах. Обязательно качайте русскую версию, так будет проще и вам и мне.
Если вы выбрали Express, то рекомендую также скачать и установить отдельно поставляемую библиотеку документации – MSDN. Для остальных версий она входит в пакет установки. Поверьте, эта документация вам еще не раз пригодится. Приступаем к работе
Будем считать, что Студию вы уже скачали и установили. Запустив ее, вы увидите вот такое окно: 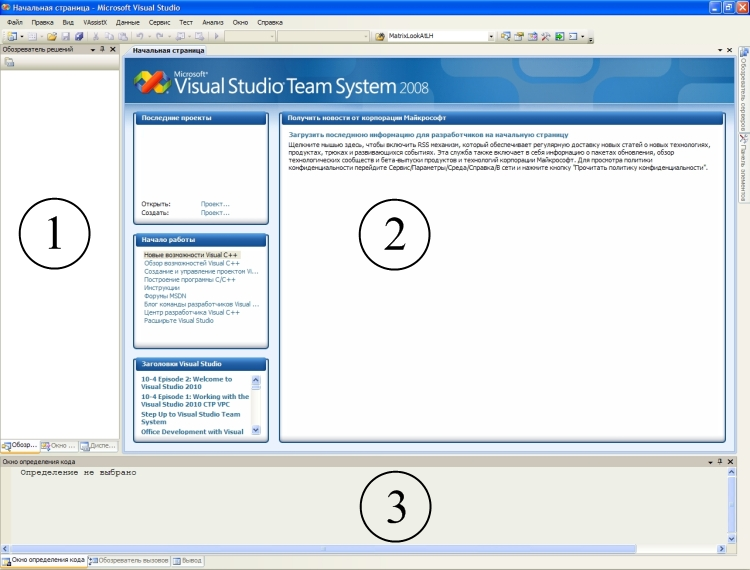 Кроме панелей инструментов, в основном окне присутствуют три области – три окна:
1. Окно, в котором сейчас по умолчанию открыт Проводник решений – нечто вроде Проводника Windows, только этот служит для навигации по файлам проекта.
2. Рабочая область – окно, в котором сейчас открыта начальная страница, а в дальнейшем здесь будет открыт файл исходного кода.
3. Окно определения кода – в этом месте, во множестве вкладок, будет выводится информация о процессе создания программы, ее работе, уведомления об ошибках и другое. Создание нового проекта
Далее для работы нам необходимо создать новый проект и добавить в него файл для исходного кода.
Делается это так:
1. Выберите пункт Файл→Создать→Проект
(подобная запись означает что вам необходимо кликнуть на пункте меню «Файл», затем в появившейся панели выбрать «Создать» и в следующей панели кликнуть на меню «Проект…») 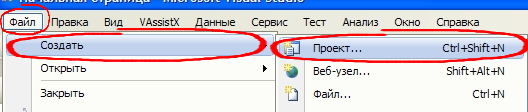 Откроется окно Новый проект. В левой его части Типы проектов необходимо кликнуть на плюсике напротив пункта Visual C++ и в открывшемся списке выбрать Win32. После этого в правой части Шаблоны выбрать «Консольное приложение Win32». Далее внизу указать имя нового проекта(у меня это Siege, вы же можете выбрать какое вам понравится), расположение каталога для проекта и поставить галочку напротив пункта «Создать каталог для решения». Имя решения будет заполнено автоматически, но при желании его можно изменить. Мы этого делать не будем. 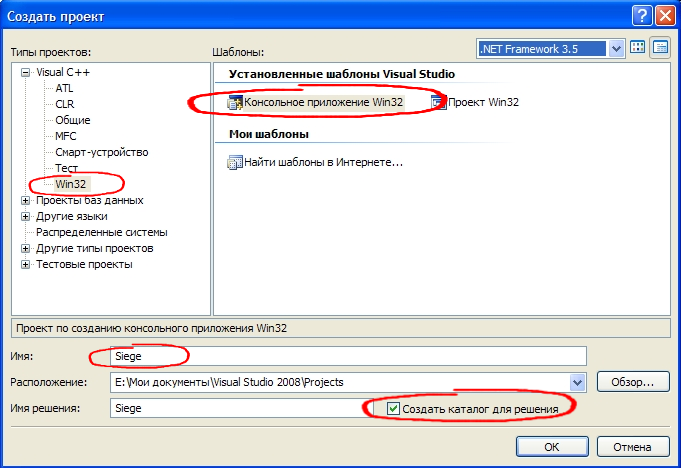 Жмем ОК.
В следующем окне Мастер приложений Win32 в левой его части выбираем пункт Параметры приложения и в правой отмечаем галочкой Пустой проект. Если этого не сделать будет создан проект с несколькими файлами и пока нежелательными для нас настройками. 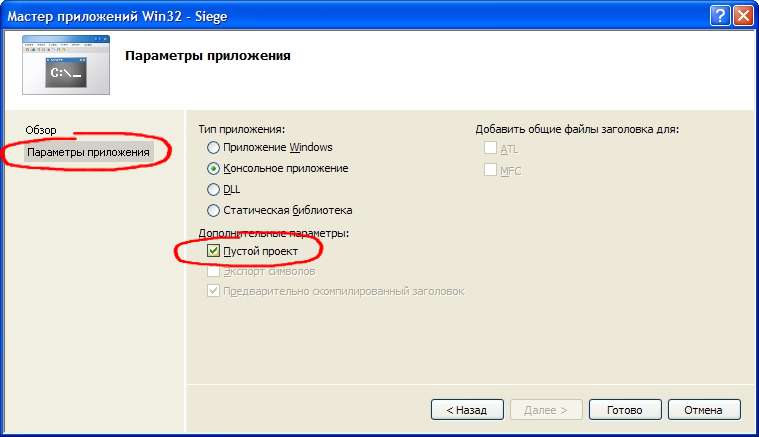 Жмем Готово.
После этого обозреватель решений примет такой вид: 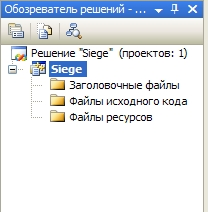 В нем появился наш проект и три папки. Папка Заголовочные файлы и Файлы исходного кода предназначены для, как нетрудно догадаться, хранения файлов исходного кода.
В папке Файлы ресурсов будут хранится всевозможные ресурсы, которые предполагается встраивать в исполняемый файл. Добавление файлов для исходного кода
Как мы и хотели ранее, проект пуст. Поэтому сейчас нам необходимо добавить файл для написания исходного кода. Делается это просто. Кликаем правой кнопкой в обозревателе решений на папке Файлы исходного кода и в появившемся контекстном меню выбираем Добавить → Создать элемент… 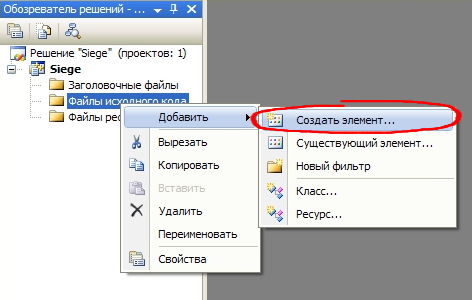 Откроется следующее окно: 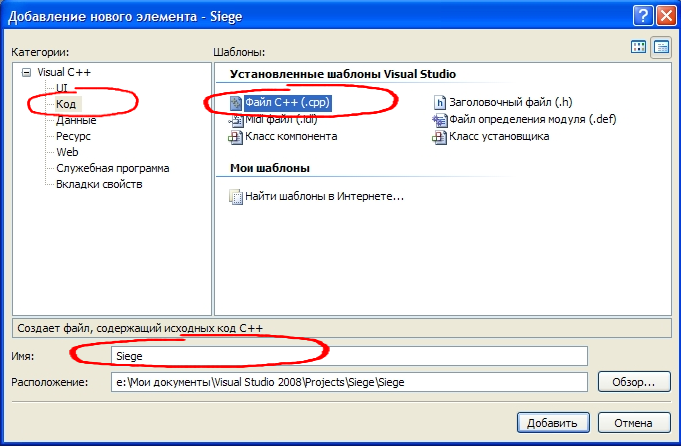 В Категориях нужно выбрать пункт Код, а в Шаблонах – Файл С++(.срр). (.срр - это формат расширения текстового файла, в котором содержатся исходные коды, написанные на языке С++.)
В строку Имя необходимо ввести желаемое имя файла.
После этого можно нажать Добавить.
В обозревателе решений в папке Файлы исходного кода должен появиться новый файл. В моем случае это Siege.cpp. 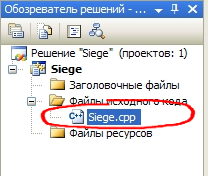 Первая программа на С++ в действии.
Пустой файл для исходного кода у нас теперь имеется, можно попробовать в действии программу, которую мы рассматривали во второй части статьи.
Производим двойной клик в обозревателе решений на нашем файле, после чего он открывается во встроенном в студию редакторе, там, где раньше была открыта начальная страница.
Далее, копируем в редактор исходный код нашей первой программы.
Как мы можем видеть - код раскрасило разными цветами. Это умная студия решила нам помочь, улучшив таким образом ориентацию в коде. Каждый цвет служит своим целям. Синий – ключевые слова, красный – строки, зеленый – комментарии, черный – иные операторы и инструкции. 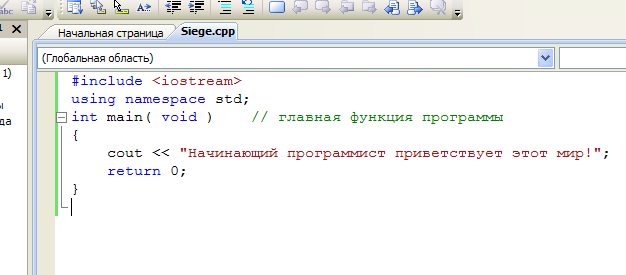 Теперь все что нам необходимо это создать исполняемую программу, или как это называется в студии - построить решение. Для этого нужно:
1. Откомпилировать исходный код.
2. Провести его компоновку, то есть собрать файлы проекта в один исполняемый файл. Делается все это нажатием всего одной кнопки - F7.
Студия быстро выполнит все необходимые действия попутно выводя отчет о работе во вкладку Вывод, открывшуюся внизу вместо «Окно определения кода». 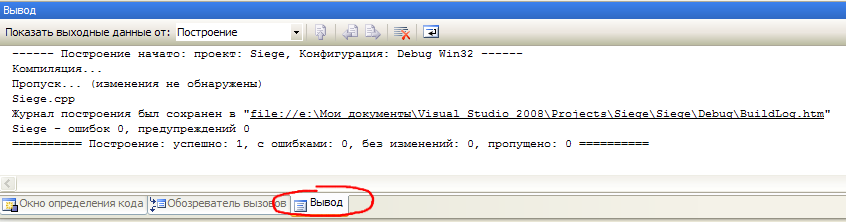 После этого приложение можно запустить, нажав комбинацию клавиш Ctrl+F5 или просто F5. Разницу между этими комбинациями мы узнаем немного позже.
При этом может появится вот такое диалоговое окно с вопросом: 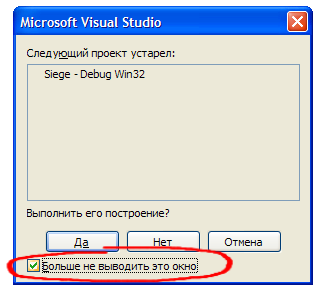 Оно означает, что с момента последнего построения в исходный код были внесены изменения. Рекомендую отметить «Больше не выводить это сообщение» и нажать Да.
Кстати, из этого также следует, что специально проводить построение нет необходимости, достаточно нажать Ctrl+F5 или F5, и если исходный код изменялся, студия откомпилирует и скомпонует его автоматически.
В общем, вы нажали кнопку, но вместо запущенной программы на долю секунды появилось и пропало черное окно. В чем же проблема? Возможно ошибка?
Нет! Посмотрев в окно Вывод можно заметить там такую строчку. Code Программа "[3724] Siege.exe: Машинный код" завершилась с кодом 0 (0x0). Ничего вам не напоминает? Объясняя код первой программы, я говорил о команде return 0;. О том, что в случае успешного завершения работы программы она возвращает ноль. «завершилась с кодом 0» - это он и есть. А значит, программа отработала так, как нужно. Все дело в том, что после того, как была отображена надпись, программа сразу же закрылась, и мы ничего не увидели. Нужно ее как-то затормозить.
Это мы сможем сделать, добавив перед return 0; следующую строчку: Она заставит окно программы оставаться открытым, пока не будет нажата любая клавиша. Внеся изменения в код, запускаем проект и появившемся окне видим следующее:  Еще одна неприятность. Вместо нашего текста выводится какая-то абра-кадабра. Все дело в том, что командная строка по умолчанию не поддерживает русский язык.
Исправить это нам поможет еще одна строчка кода, которая настроит консоль на правильное отображение русских букв: Code setlocale( LC_ALL, "Russian" ); Поместить ее необходимо внутри функции main перед выводом текста: Code setlocale( LC_ALL, "Russian" );
cout << "Начинающий программист приветствует этот мир!"; После этого все заработает так, как нужно и после запуска появится вот такое окно. 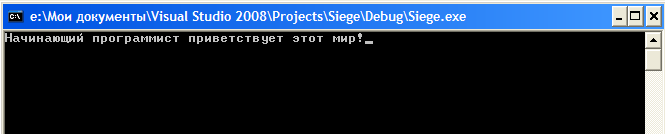 Что ж, поздравляю. На этом знакомство с основами работы с Microsoft Visual Studio завершено. В процессе обучения я, по мере необходимости, буду давать информацию на этот счет, а пока вы узнали все, что нужно.
Прежде чем переходить к освоению следующего материала, советую немного поиграться со Студией, потыкать кнопочки, поковырять менюшки. На данном этапе вам необходимо освоиться с этой средой разработки и только после этого следовать дальше.
Windmill 2
WindMill 2D Game Engine
|
|
|
| |
| nilrem | Дата: Среда, 19 Августа 2009, 00:11 | Сообщение # 2 |
|
Просветленный разум
Сейчас нет на сайте
| 5. Мини игра «Осада» Теперь, приобретя некоторые знания, попытаемся написать небольшую игру. А как же иначе, ведь мы будущие программисты игр. В процессе ее разработки мы освоим такие новые элементы языка как переменные, операторы и ввод-вывод. Планирование
Каждый проект должен начинаться с тщательного планирования. Прежде чем приступить к работе, необходимо решить, что же именно мы будем писать, как это будет реализовано и что для этого понадобится.
Значит, идем по порядку.
Что же именно мы будем делать.
Поскольку наши знания пока еще весьма скудны, ничего сложного написать не получится. Поэтому делать будем простенькую игру об осаде замка. Суть ее будет в том, что у вас есть армия, состоящая из четырех видов войск. В свою очередь каждую стену замка также охраняет определенный вид воинов. В процессе игры необходимо точно определить, кому кого противопоставить, поскольку из всех войск только один их вид способен победить конкретного противника. Если все войска противника погибли, то вы захватили замок, то есть выиграли. Если хоть кто-то выжил, то вы проиграли. Как это будет реализовано.
Реализовано это будет в виде диалога. Программа сначала выводит небольшое сюжетное введение, а затем последовательно запрашивает у вас данные, и в конце выводит результат. Также в выводимом тексте должны содержаться подсказки по управлению программой. Что для этого понадобится.
Программа сначала выводит небольшое сюжетное введение, а следовательно для этого мы должны ознакомится с таким понятиями как ввод-вывод и текстовые строки. Ввод-вывод текстовой информации
Каждая игровая программа, чтобы быть хоть чуточку интересной, должна как-то взаимодействовать с пользователем, ну а в нашем случае - с игроком. То есть она должна выводить определенную информацию и принимать определенные данные. Делая разбор первой программы, мы уже печатали на мониторе текст "Начинающий программист приветствует этот мир!".
Для этого мы воспользовались инструкцией cout. Синтаксис ее такой. Code cout << «ВЫВОДИМЫЙ ТЕКСТ»; cout воплощает в себе стандартное средство вывода, то есть монитор.
Две стрелки(<<) – это специальный оператор потока(поток – последовательность символов или данных вообще). Если говорить по-простому, то этот оператор запихивает наш текст в cout, выводя его таким образом на экран.
Согласно правил, строка текста – это набор символов, заключенных в кавычки. Так компилятор узнает, с чем он работает. В качестве выводимого текста могут быть также и числа. В таком случае кавычки не требуются. Но как же нам вывести сами кавычки, ведь они будут восприниматься как начало или конец строки текста.
То есть вот такая запись будет не верной, и компилятор выдаст ошибку. Для того чтобы все работало так как нужно, используются специальные управляющие символьные последовательности. Кроме того эти последовательности дают возможность выполнить незначительное форматирование выводимого текста. Все управляющие символьные последовательности начинаются с обратного слеша - \ (наклоненная влево вертикальная черта).
Вот некоторые из них: \a Сигнал
\b Возврат курсора на символ назад
\t Горизонтальная табуляция
\n Переход на новую строку
\v Вертикальная табуляция
\r Возврат курсора на строку вверх
\" Кавычки
\' Апостроф
\0 Ноль-символ
\\ Обратный слеш
\? Вопросительный знак Теперь, зная их, вместо предыдущего варианта достаточно написать: и все заработает.
Думаю, настало время немного поиграться. Откройте, если она еще не открыта, созданную ранее первую программу, и подставьте в строчку: Code cout << "Начинающий программист приветствует этот мир!"; в любое понравившееся место выводимого текста, одну из представленных символьных последовательностей. Запустите программу и полюбуйтесь на результат. Наигравшись досхочу, можем переходить к изучению дальнейшего материала. Открою вам один маленький, но неприятный момент. Максимальная длина строки выводимого текста – 256 символов. Если ваш текст окажется длиннее, то все что не поместилось, просто будет отброшено. В общем-то, ничего страшного, ведь на практике редко встречаются такие длинные предложения.
Чтобы напечатать большое количество текста просто достаточно воспользоваться двумя, тремя или вообще любым количеством операторов cout. Вот так это будет выглядеть: Code cout << "Допустим что в этом тексте 150 символов.";
cout << "И в этом 150";
cout << "Ура, мы напечатали намного больше, чем 256 символов."; Вышеуказанный пример можно немного сократить. Синтаксис языка допускает такой вариант оформления: Code cout << "Допустим что в этом тексте 150 символов." << "И в этом 150" << "Ура, мы напечатали намного больше, чем 256 символов."; Как в первом, так и во втором варианте текст будет выведен в одну строку. Каждый следующий cout начинает вывод в том месте, где остановился предыдущий.  Предположим что нам необходимо, чтобы последнее предложение начиналось с новой строки. Для этого достаточно в его начало, или в конец предыдущего, вставить управляющий символ \n. Вот так: Code cout << "Допустим что в этом тексте 150 символов." << "И в этом 150" << "\nУра, мы напечатали намного больше, чем 256 символов."; И мы получим:  Что и требовалось. Ну что ж. С выводом данных разобрались, теперь рассмотрим ввод. Для этих целей используется оператор cin. Его мы тоже уже немного упоминали раньше.
Также как и cout, cin ассоциируется с реальным устройством, но в его случае это стандартное устройство ввода – клавиатура. После набора данных и нажатия Enter, вся введенная информация достается cin. Вот синтаксис его использования. cin >> переменная; Здесь >> - все тот же поток, но теперь он получает из cin введенные данные и передает их в какую-то переменную. Чтобы следовать в нашем обучении дальше, теперь нам необходимо познакомится с этими самыми переменными. Переменные. Типы данных.
В своей игре нам нужно в каком то виде представить и хранить наши войска. Со словом хранить в первую очередь ассоциируется такая вещь, как сундук. В языке с++ такими сундуками выступают переменные.
В программировании, как и в математике под переменной подразумевают некую величину, которая при необходимости может варьироваться. Опять на ум приходит то же сундук, в который можно что-то класть, что-то забирать. Также как сундук может быть приспособлен для хранения определенных вещей, так и переменные могут относится к определенному типу данных.
В языке программирования С++ используются основные данные такого типа:
void (Пустой тип) – как это ни парадоксально, но в С++ есть тип, который указывает на отсутствие информации.
char (Символьный тип) – в переменных этого типа может храниться один символ, то есть буква, спецсимвол, одна цифра и другие.
int (Целое число) – как понятно из названия используется для хранения целых чисел.
float (Число с плавающей точкой) – понятно и так, но на всякий случай приведу пример. Это числа вроде – 1.5, 127.52, 0.5867. То есть это числа, в которых присутствуют десятые, сотые, тысячные и т.д.
double – улучшенная, более точная версия float, отличается тем, что в нее вмещается больше цифр после точки.
bool (Логический тип) – очень простой, но весьма важный тип. Может иметь всего два значения – правда и ложь(true и false). Любой из перечисленных выше типов может содержать в себе это логическое значение. Просто если значение есть то это true, а если его нет или оно равно нолю то это false. Возможно, вам покажется что их мало, но смею вас заверить, что такого их количества нам будет вполне достаточно для любой программы. Если это вас не утешило, могу вас обрадовать, позже мы познакомимся и с другими, а также научимся создавать собственные.
Кроме того что переменная имеет тип, она еще имеет и название ну и естественно какое-то значение. Сейчас я расскажу вам, как создавать, или если использовать терминологию программирования – объявлять, в своей программе переменные определенных типов. Синтаксис этого действия весьма простой: Тип_данных Имя_переменной; Думаю, тут все просто. Сначала идет тип данных, затем имя переменной и заканчивается все неизменной точкой с запятой.
Пример:
Code int i;
void Ha;
bool Pravda;
float f; Разбирая объявления нельзя не упомянуть об именах переменных и некоторых правилах:
1. Имя должно содержать только символы латинского алфавита.(В Microsoft Visual Studio 2005/2008 допускается использование кирилицы, тоесть имена можно писать на русском языке)
2. Имя может включать любые другие символы, кроме специальных(!@#$%^&*()+-=/.,<>).
3. Имя должно начинаться только буквой, также допускается символ подчеркивания(_).
4. Имя должно быть уникальным. Двух переменных с одинаковыми именами, пусть даже и разных типов, быть не должно.
5. Имя переменной не должно совпадать с зарезервированными словами.(Зарезервированные слова это слова за которыми в языке программирования С++ закреплены определенные действия или значения. Например include, или типы данных int, bool и т.д. Редактор Microsoft Visual Studio выделяет такие слова синим цветом). Добавлю еще кое-что. Компилятор языка С++ делает четкое различие между одинаковыми буквами но в разном регистре.
То есть здесь: с точки зрения компилятора было объявлено две разные переменные. И еще один пример: Code int variable;
int Variable;
int vARIABLE;
int vaRiable;
int variablE; Все эти переменные также считаются разными.
Скажу еще немного об объявлении. Две и больше переменных одного типа, можно объявить, разместив их в ряд через запятую, после типа данных. Вот так: Здесь х, y, z, cell – целочисленные переменные. Ну вот, с объявлением переменных разобрались. Теперь нам нужно уяснить такую вещь. Сами по себе переменные никому не нужны. Важным является лишь содержащееся в них значение, и без разницы символ это, число, или логическое выражение. Поэтому сейчас я расскажу, как это значение переменной присваивается. Для этого используется специальный оператор присвоения. Логично, да? Вот синтаксис присвоения: Тип_данных Имя_переменной = ЗНАЧЕНИЕ; Здесь символ равно (=) это и есть оператор присвоения. Все просто. Но не настолько, как вы подумали. Вот пример: Code int i = 127;
bool Pravda = true;
float f = 1.5f;
char c = 'c'; Думаю с типом int и bool все понятно, а вот что это за странное число - 1.5f. Приписанная в его конце буква f означает, что это число с плавающей точкой, то есть – float. Вообще-то можно обойтись и без этой f. Все равно компилятор правильно его обработает. По большему счету, такая запись просто улучшает ориентацию в коде(или если говорить языком программистов – улучшает читабельность).
Ну и напоследок осталось разобраться с типом char. Относящиеся к нему данные в языке С++ записываются заключенными в одинарные кавычки, как выше и показано в примере.
Также следует знать, что значение переменным можно присваивать не только во время их объявления, но и позже. Вот так: Ну и естественно, значения одних переменных, можно присваивать другим: Code int х;
х = 777;
int у = х; Хранящиеся в сундуке вещи не приносят никакой пользы их владельцу. Так и с переменными. Они должны для чего-то использоваться, взаимодействовать между собой, и как-то меняться. Переменные все-таки. Для работы с «числовыми» типами данных используются специальные арифметические операторы. Их мы дальше и рассмотрим. Арифметические операторы
Ну, назвав их специальными, я немного погорячился. На самом деле они знакомы нам со школы. Это те же самые: 1. * (умножение),
2. / (деление).
3. +(сложение).
4. - (вычитание), Думаю, объяснять, что они делают, не нужно, и пока что нам их хватит. В дальнейшем, по мере необходимости я познакомлю вас и с остальными. Да с остальными, ведь не думаете же вы, что в таком мощном языке как С++ всего четыре арифметических оператора.)
Строка кода, содержащая переменные, числа и арифметические операторы называется – выражение. В одном выражении может содержаться сколько угодно операторов: Code int х = y + 256 - 13 * z / 3; Надеюсь, вы помните со школы, что арифметические операторы имеют приоритет выполнения. Если нет, то я вам напомню. Выше по тексту в списке операторы расположены согласно их приоритета. То есть наивысший приоритет имеет умножение, оно будет выполнено в первую очередь, а вычитание будет выполнено последним.
Но самый низкий приоритет среди операторов имеет оператор присвоения (=). В выражении он всегда выполняется последним, присваивая результат вычислений переменной.
Если нам нужно чтобы вычисление в выражении произошло в иной последовательности чем это предписано приоритетами, то необходимо использовать скобки. Code int х = y + (256 – 13) * (z / 3); В этом случае сначала будет выполнено вычитание и деление, а уже затем, согласно приоритета операторов – умножение, а за ним сложение.
Надеюсь что вы еще не устали. На текущий момент это вся информация, которую вам необходимо знать об арифметических операторах. Так что можете немного отвлечься и пойти погулять. «Осада»
Наконец- то мы добрались до этого места. Сейчас, используя все полученные знания, мы напишем свою первую игру. Раньше мы уже определились, что будем делать, и как это будет реализовано. Ну а в последних разделах я только и делал, что объяснял основы языка программирования, которые нам для этого понадобятся.
В самом начале обучения мы уже написали первую программу. Сейчас мы внесем в нее необходимые изменения, чтоб она превратилась в небольшую игру.
Приступаем к самой интересной части.
Как уже было оговорено раньше, наша игра сначала должна вывести небольшое сюжетное введение. Вы же помните, что за вывод текста у нас отвечает оператор cout. Откроем в редакторе студии ранее созданные файл с исходным кодом, у меня он называется Siege.cpp (siege – с английского «Осада»), и вместо имеющейся там строчки вывода приветствия, добавим следующий код: Code cout << "После долгого, долгого перехода вы наконец-то добрались к окресностям форта,\n";
cout << "который приказом короля вам велено захватить.\n";
cout << "Но, как выяснилось, форт хорошо охраняется:\n\n";
cout << "Южные ворота охраняет Дракон.\n";
cout << "Северную стену - Голем.\n";
cout << "На восточной расположились лучники,\n" ;
cout << "а на западной - крестьяне.\n\n"; Думаю теперь, после моих объяснений, в этом коде вам должно быть все знакомо. У нас здесь есть оператор cout, оператор потока и строки с текстом. Поскольку символов в тексте намного больше, чем допускается, каждую строчку я вывел с помощью отдельного оператора. Чтобы выводимый текст было удобнее читать, он отформатирован с помощью известного вам символа - \n.
Как видно из введения, форт охраняется четырьмя видами войск. Для их представления нам необходимо обьявить четыре целочисленные переменные. Как это сделать, вы уже знаете. Также нам необходимо присвоить им определенные значения. Их необходимо выбрать так, чтобы только в одной комбинации нападающих и защищающихся войск все защитники погибли, то есть, чтобы в соответствующей паре значения совпадали, в таком случае результат их вычитания будет равен нолю.
Я сделал так: Code int Draco=2; // Дракон
int Golem=4; // Голем
int Arrows=3; // Лучники
int Peasant=1; // Крестьяне Дальше по сюжету нам необходимо выбрать, на какую стену, то есть против какого противника кого из воинов послать. Список воинов с их порядковыми номерами и небольшой инструкцией выводим следующим кодом: Code cout << "Ваша армия состоит из\n";
cout << "1. Асасинов\n";
cout << "2. Магов\n";
cout << "3. Латников\n";
cout << "4. Катапульты\n\n";
cout << "(Для выбора вариант ответа вводите соответствующий номер и нажимаете ENTER.\n";
cout << "Выбрать войска можно только один раз.)\n\n";
cout << "Кого вы отправите против Дракона?\n";
.
Здесь тоже все должно быть понятно. В последней строке программа задает вопрос, на который ожидает ответ. То есть далее предполагается получение от пользователя определенных данных. Эти даные нужно где-то хранить, поэтому нам необходимы еще целочисленные переменные. Но поскольку их ввод будет производится последовательно, после каждого введенного числа можно проводить вычисления для отдельного типа войск. Поэтому для ввода нам будет достаточно всего одной переменной. Как видим, значение у нее нет, поскольку оно в последствии будет получено от пользователя. Вспоминаем что ввод осуществляется с помощью оператора cin и добавляем необходимый код: Здесь программа получит введенное число и передаст ее в переменную i.
После того как даные получены, выполняем вычисления для текущего защитника и нападающего. Для этого используем вот такое простое выражение. Если значениями Draco и i является одинаковое число, то результат вычисления будет равен нолю, что нам и нужно. У меня драконам соответствую маги, големам – катапульта, лучникам – латники а крестьянам – асасины. Поэтому значение переменных в этих парах должно быть одинаковое. Добавим код и для остальных войск. Не забываем выводить запрос, получать введенные данные и проводить вычисления. Code cout << "Кого вы отправите против Голема?\n";
cin >> i;
Golem = Golem - i;
cout << "Кого вы отправите против лучников?\n";
cin >> i;
Arrows = Arrows - i;
cout << "Кого вы отправите против крестьян?\n";
cin >> i;
Peasant = Peasant - i; Теперь, когда все данные получены, вычисления произведены можно выводить результат, добавив к нему описание условия победы или поражения: Code cout << "У противника осталось " << Draco << " Драконов, "<< Golem << " Големов, "<< Arrows << " Лучников, "<< Peasant << " Крестьян\n." << "Если войск у противника не осталось - ВЫ ВЫИГРАЛИ"; Как видно из кода, я воспользовался вторым способом вывода, без повторного использования оператора cout. Но в коде, вместо текстовых строк присутствуют используемые для войск переменные. Как я уже упоминал, само имя переменной для программы не важно, она работает с ее значением. Поэтому вместо имен переменных в тексте будут напечатаны их значения. Переменная – это не текст, так что ее имя в кавычки заключать не нужно.
На этом написание нашей первой игры завершено. Добавлю лишь некоторые моменты. Обьявление переменных желательно проводить в начале кода, так сразу будет понятно, какими данными управляет программа.
Строка для вывода данных в конце прграммы получилась слишком длинной и в редакторе вышла за пределы экрана, что неудобно. Поэтому ее можно разбить на несколько частей вставив перенос строки(клавиша Enter). При этом важно знать что разбивать на части операторы, имена переменных или строки нельзя. Подобное будет воспринято компилятором как ошибка. Вот такая запись не правильная: Code cout << "У противника
осталось " << Draco <<
" Драконов, "<< Golem <
< " Големов, ";
Нужно так: Code cout << "У противника осталось "
<< Draco <<
" Драконов, "<< Golem <<
" Големов, "; Вот полный исходный код нашей игры: Code #include <iostream>
using namespace std;
int main( void ) // главная функция программы
{
setlocale( LC_ALL, "Russian" ); // задействование русского языка
int Draco=2; // переменная для Дракона
int Golem=4; // голем
int Arrows=3; // лучник
int Peasant=1; // крестьянин
int i=0; // переменная для хранения введенного игроком числа
// Вывод вступительного текста
cout << "После долгого, долгого перехода вы наконец-то добрались к окресностям форта,\n";
cout << "который приказом короля вам велено захватить.\n";
cout << "Но, как выяснилось, форт хорошо охраняется:\n\n";
cout << "Южные ворота охраняет Дракон.\n";
cout << "Северную стену - Голем.\n";
cout << "На восточной расположились лучники,\n" ;
cout << "а на западной - крестьяне.\n\n";
cout << "Ваша армия состоит из\n";
cout << "1. Асасинов\n";
cout << "2. Магов\n";
cout << "3. Латников\n";
cout << "4. Катапульты\n\n";
cout << "(Для выбора вариант ответа вводите соответствующий номер и нажимаете ENTER.\n";
cout << "Выбрать войска можно только один раз.)\n\n";
cout << "Кого вы отправите против Дракона?\n";
cin >> i; // получение данных от игрока
Draco = Draco - i; // вычисление результата для Дракона
cout << "Кого вы отправите против Голема?\n";
cin >> i; // получение данных от игрока
Golem = Golem - i; // вычисление результата для Голема
cout << "Кого вы отправите против лучников?\n";
cin >> i; // получение данных от игрока
Arrows = Arrows - i; // вычисление результата для Лучников
cout << "Кого вы отправите против крестьян?\n";
cin >> i; // получение данных от игрока
Peasant = Peasant - i; // вычисление результата для Крестьян
// Вывод результата вместе с условиями выиграша
cout << "У противника осталось " << Draco << " Драконов,"
<< Golem << " Големов, "<< Arrows << " Лучников, "<< Peasant <<
" Крестьян\n." << "Если войска остались - ВЫ ПРОИГРАЛИ";
cin.get(); // ожидание нажатия клавиши
cin.get(); // ожидание нажатия клавиши
return 0; // возвращение значения, и завершение программы
}
В конце программы есть некоторая конструкция, которую я считаю нужным обьяснить. Code cin.get(); // ожидание нажатия клавиши
cin.get(); // ожидание нажатия клавиши С cin.get() мы уже знакомы. Она используется для того, чтобы заставить нашу программу подоздать нажатия клавишы. Но почему она дублируется?
Все очень просто. При вводе чисел вы подтвержнаете эту опрацию нажатием клавиши Enter. Так вот это нажатие и будет воспринято cin.get() и программа сразу же завершится. Чтобы этого не произошло, строка cin.get(); написана дважды. Теперь вы со всем разобрались, конечно игра получилась слишком простая и не совсем корректная, зато ее можно уже запускать и играть, если бы не одно но…
Всегда есть это но. Кто вам сказал, что она у вас запустится?
Windmill 2
WindMill 2D Game Engine
|
|
|
| |
| nilrem | Дата: Среда, 19 Августа 2009, 00:12 | Сообщение # 3 |
|
Просветленный разум
Сейчас нет на сайте
| 6. Снова IDE. Работа с ошибками. Хорошо, когда все работает так, как нужно. Если вы были внимательными и тщательно следовали изложенным инструкция, то проблем у вас не должно возникнуть.
Но никто не застрахован от ошибок. В программировании малейшая неточность приводит к тому, что программа работает не так, как нужно, а то и вовсе не работает, даже не компилируется.
В этой части я специально сделаю ошибки, проиллюстрирую, как на них отреагирует среда разработки, и расскажу, как их исправлять.
Дальнейший материал я буду объяснять с той позиции, что у меня все работает. Не спешите ругаться, мол - у вас наоборот, ничего не запустилось. Может так случиться, что дочитав до конца, вы без труда сможете исправить все ошибки, и все имеющиеся сейчас вопросы сами собой отпадут.
Приступаем к работе. Запускаем студию и открываем в ней наш, уже существующий проект. Сделать это можно многими способами, но я упомяну самые простые. При запуске студии автоматически запускается начальная страница, на которой есть список последних проектов.  Если же вы слишком шустрые и уже успели эту страницу закрыть, то делаем следующее. Нажимаем пункт меню Файл→Последние проекты и в появившемся списке выбираем тот, что нужно. Главное помнить, как он называется) 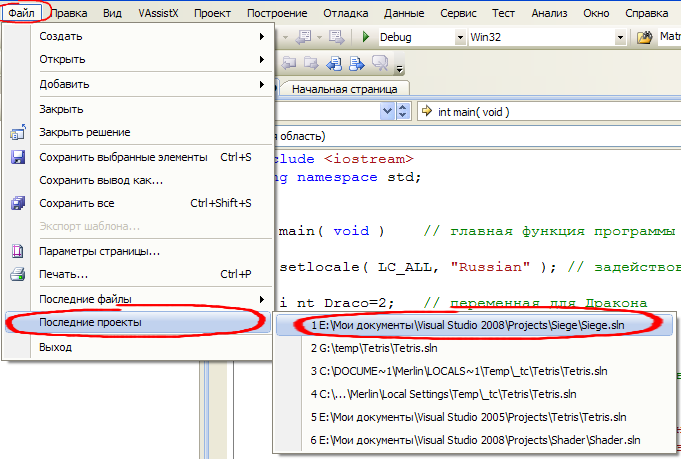 image017 image017 Открываем файл с исходным кодом, если это не было сделано автоматически, и портим его ошибками
Первое, что мы сделаем это в строке: Code int Draco=2; // переменная для Дракона в названии типа данных int вставим пробел, разбив его таким образом на два слова. Вот так: Code i nt Draco=2; // переменная для Дракона Теперь можем запускать процесс компиляции. Естественно программа работать не будет. При неудачной компиляции студия может предложить вам запустить предыдущую, успешно откомпилированную программу. Нас интересует только свежая программа, поэтому вестись на ее уговоры не нужно.
Во вкладке Вывод, которая, как вы помните находится внизу окна студии, появится информация о процессе компиляции: 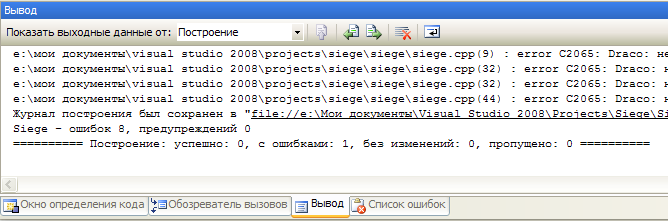 В самом низу появившейся информации строчка «с ошибками: 1 » указывает на то, что ваш проект содержит ошибки. Экая новость, мы об этом и так знаем. Кроме того что студия может нам сообщить о наличии ошибок, она так же может и указать на них.
Рядом с вкладкой Вывод есть вкладка Список ошибок.
Если ее почему то нет, но найти ее можно так:
Выбираем пункт меню Вид → Другие окна → Список ошибок.  Если раньше этой вкладки не было, то теперь она обязательно появится. Вот как она выглядит: 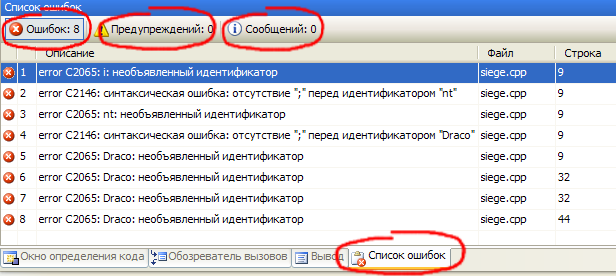 Я распишу вам его немножко поподробнее. Прямо под названием окна находится три кнопки, сообщающие о количестве найденных в программе ошибок, предупреждений или сообщений. Если все кнопки включены, то все перечисленное будет выводится ниже в окне, если же какая-то из них, или даже все, будет отключена, то соответствующая ей информация выводится не будет. Поскольку предупреждения и сообщения не мешают процессу компиляции, сейчас нас интересуют только ошибки. Так что если кнопка еще не нажата, то сделаем это.
Кстати, вы уже заметили, что ошибок восемь, а делали мы вроде всего одну. Такова судьба программиста. Малейшая ошибка может повлечь за собой страшные последствия. Допустив всего одну неточность в исходном коде, мы, сами того не ведая, сразу нарушили несколько правил языка, что и привело до появления такого количества ошибок при компиляции. А представьте, если в коде ошибок больше. Но не будем отвлекаться.
Произведем двойной клик на стоке с первой ошибкой. В ответ на наше действие среда разработки укажет нам в исходном коде на строчку, в которой эта ошибка находится. 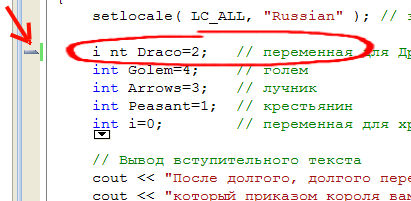 Теперь прочитаем описание ошибки и внимательно рассмотрим указанную редактором строку.
Мы помним, что в этом месте должно быть объявление переменной для дракона. Если вы хорошо помните синтаксис объявления, ошибка будет обнаружена и исправлена без труда. В противном случае рекомендую перечитать предыдущий материал статьи.
После правки предполагаемой ошибки вновь запускаем компиляцию, если ошибка исправлена, то сообщения о ней мы больше не увидим, и, если ошибок нет, то естественно программа заработает.
Существует огромное количество разнообразных ошибок. Описать их все просто не реально. Но внимательно читая описание ошибки, и, вооружившись знаниями, тщательно проверяя содержащую ее строку кода, можно постепенно исправить их все. Главное в этом занятии – терпение, и рано или поздно оно будет вознаграждено работающей программой. 7. Послесловие. Поздравляю, вот вы и написали свою первую игру. Вернее мою игру. Но что теперь вам мешает написать собственную. Используя полученные знания, попытайтесь сделать что-то свое. Придумайте сюжет, воплотите его в код. Можете считать это домашним заданием.
Сегодня, познав самые азы С++, вы сделали очень важный шаг в своей жизни. Кто знает, возможно когда-то вы станете известным программистом и напишете десятки превосходных игр с восхитительной графикой, но могу поспорить что эту свою, примитивную и лишенную графики первую игру, вы запомните навсегда.
На этом все.
До встречи в следующих уроках.
Windmill 2
WindMill 2D Game Engine
|
|
|
| |
| nilrem | Дата: Пятница, 11 Сентября 2009, 18:23 | Сообщение # 4 |
|
Просветленный разум
Сейчас нет на сайте
| Статья 2 : Продолжаем обучение. Здравствуйте, уважаемые, жаждущие знаний, читатели. Прошло довольно много времени, у меня наконец то выдалась свободная минутка и я продолжаю начатое знакомство с языком программирования С++. Надеюсь что вы не теряли времени даром, поскольку делать столь длительные перерывы в обучении не то что не желательно, а даже вредно. Есть такое крылатое выражение – «Учится, все равно, что грести против течения, только перестанешь и тебя гонит назад». Поскольку писать уроки в спринтерском темпе у меня вряд ли получится, дабы исключить такие длительные перерывы и утолить жажду знаний, советую найти где-нибудь книгу по программированию. Могу посоветовать «С++ для чайников», брать что либо серьезнее не рекомендую, поскольку могут возникнуть проблемы с пониманием материала, вследствие чего вы оставите книгу пылится где-то на полке и плюнете на саму мысль об обучении С++. Все таки это не самый легкий для изучения язык.
Ладно, хватит пудрить мозги, пора грести против течения. 1. Совершенствуем «Осаду» Созданная на прошлом уроке игра работала не совсем корректно. Кроме того что все расчеты в ней очень примитивные, она еще и предлагала игроку самому решать выиграл он или проиграл. Сейчас мы будем это исправлять. Конечно, для этого нам необходимо освоить новый материал. Как я уже говорил на прошлом уроке, нужно ставить перед собой конкретные задачи.
На данный момент это:
1. Проверить, остались ли у замка защитники.
2. В зависимости от полученного результата, вывести соответствующее сообщение. Проверка защитников осуществляется очень просто, и как мы помним из условия, их количество должно быть равно нолю. Поэтому сейчас мы узнаем, как сравнивают между собой переменные. Логические операторы и операторы сравнения Помните что такое логический тип данных. Это такая вещь, которая может иметь только два значения истина или ложь(true или false, ведь на русском компилятор не понимает).
Логический оператор помещается между двумя аргументами(переменными), и в результате совершения определенных действий над ними возвращает логическое значение. Вот перечень логических операторов: ! – оператор НЕ. Он применяется всего к одной переменной, изменяя ее логическое значение на противоположное.
Пример:
!true возвратит false
!false возвратит true
(заметьте, после восклицательного знака пробела нет ) && - оператор И. Возвращает true если оба аргумента истинны. В любом другом случае возвращает ложь.
Пример:
true && true возвратит true
true && false возвратит false
false && false возвратит false || - оператор ИЛИ. Возвращает true если один из аргументов истина.
Пример:
true || true возвратит true
true || false возвратит true
false || false возвратит false Откуда берутся приведенные в примерах true и false. Чаще всего они появляются в результате работы логических операторов, которые также являются операторами сравнения. > - оператор больше. Возвращает true если значение левого аргумента больше чем у правого.
Пример:
10 > 5 возвратит true
10 > 10 возвратит false
10 > 15 возвратит false >= - оператор больше или равно. Возвращает true если значение левого аргумента больше или равно правому.
Пример:
10 >= 5 возвратит true
10 >= 10 возвратит true
10 >= 15 возвратит false < - оператор меньше. Возвращает true если значение левого аргумента меньше чем у правого.
Пример:
10 < 5 возвратит false
10 < 10 возвратит false
10 < 15 возвратит true <= - оператор меньше или равно. Возвращает true если значение левого аргумента меньше или равно правому.
Пример:
10 <= 5 возвратит false
10 <= 10 возвратит true
10 <= 15 возвратит true == - оператор равно. Возвращает true если значение левого аргумента равно правому. Важно не путать с арифметическим оператором присваивания =. Эта ошибка очень часто встречается у начинающих, и не только, программистов. Компилятор на нее никак не реагирует, в следствии чего возникает много неприятностей, поэтому необходимо быть внимательным.
Пример:
10 == 5 возвратит false
10 == 10 возвратит true
10 = 10 ничего не возвратит, так как это оператор присваивания. != - оператор не равно. Возвращает true если значение левого аргумента не равно правому.
Пример:
10 != 5 возвратит true
10 != 10 возвратит false Как и в случае с арифметическими операторами, логические также имеют приоритет.
Как это ни странно, наивысший приоритет имеет !. Далее идут операторы сравнения, они изложены попарно в порядке снижения приоритета. За ними идут && и ||. Операторы с одинаковым приоритетом выполняются слева направо. Не буду приводить вам никаких примеров с приоритетами, кто захочет - разберется сам, а кто не захочет – будет пользоваться скобками.
Теперь я приведу вам один интересный пример. Компилятор С++ допускает такое выражение: Как вы думаете, что будет возвращено после вычисления этого выражения?
Если смотреть с точки зрения математики, то это выражение должно быть ложным. Но мы будем рассматривать его с точки зрения логики программирования.
Начнем разбор. В соответствии с одинаковыми приоритетами сначала будут сравниваться 10 и 7, а затем их результат будет сравнен с цифрой 5. В результате первой операции будет получено значение false, поэтому выражение примет такой вид: Как же нам теперь сравнить логическое значение с числовым. Помните, я при знакомстве с типами данных упоминал, что если значение есть то это true, а если его нет, то это false. Учитывая это наше выражение примет такой вид: Теперь вы должны запомнить, согласно здравой логики наличие значения(конечно, если это не ноль) всегда больше чем его отсутствие, то есть true больше чем false, поэтому наше выражение истинно и оператор сравнения возвратит true. Вот так то.
Кстати, я нигде не видел использования приведенного выше трио, так что все рассуждения приведены здесь в общеобразовательных целях. Если вы в них ничего не поняли, то это не страшно. Подозреваю, что все написанное выше было так же нудно читать, как и писать. Поэтому дабы не нагонять скуку, переходим к следующему пункту. Нам нужно сравнить переменные, обработать результат этого сравнения и определиться с дальнейшими действиями. Для этой цели используется оператор выбора. Операторы ветвления, выбора и условный оператор. Операторами выбора называются операторы, которые в результате проверки определенных условий выбирают какое действие, будет выполнятся дальше.
Существует два вида операторов выбора: пара if else и switch. if else Это, наверное, самый важный оператор в программировании. И самый мощный. Если сейчас мы будем использовать его всего лишь для определения, победил игрок или получил поражение, то в дальнейшем на нем будут строится системы искусственного интеллекта для наших игр. Вот так то. Поэтому к его изучению необходимо отнестись с должной серьезностью.
Вообще-то сам по себе он не очень сложный. Вот синтаксис его самого простого варианта: Code
if (условие)
{
Блок кода
}
Работает оператор так. Сначала проверяется условие, если оно истинно то выполняется Блок кода. Если условие ложно, то код пропускается.
Если в блоке кода находится всего одна строка, то фигурные скобки можно не ставить. Пример: Code
if (условие)
Блок кода
Если, как и в нашем случае, необходимо проверить несколько значений, то используется несколько операторов if Code
if (условие)
{
Блок кода
}
if (условие)
{
Блок кода
}
if (условие)
{
Блок кода
}
Но в этом случае все последующие условия будут проверяться даже если какое-то из предыдущих оказалось истинным. Чтобы избежать это используется полный вариант оператора ветвления. Вот его синтаксис: Code
if (условие)
{
Блок кода
}
else
{
Блок кода
}
В этом случае Блок кода после else будет выполнен, только если условие ложно.
Поэтому если сделать так: Code
if (условие)
{
Блок кода
}
else
{
if (условие)
{
Блок кода
}
if (условие)
{
Блок кода
}
}
То второй и третий операторы будут выполнены, только если условие первого ложно. Но при этом они также будут выполнены не зависимо от истинности условий друг друга. Поэтому самый правильный вариант такой: Code
if (условие) // первый оператор
{
Блок кода первого оператора
}
else
{
if (условие) //второй
{
Блок кода второго
}
else
{
if (условие) //третий
{
Блок кода третьего
}
}
}
Теперь будет выполнен только один, соответствующий условиям и стоящий первым, оператор, даже если условие истинно для еще какого-то из последующих. И чтобы лучше понять изложенный материал приведу вот такой небольшой пример: Code
if(a==5)
cout<<"Введенное число равно пяти";
else
{
if(a>5)
cout<<"Введенное число больше пяти";
else
{
if(a<5)
cout<<"Введенное число меньше пяти";
}
}
Пройдемся по примеру. Допустим, что переменная а это некоторое введенное пользователем значение от 0 до 10. Сначала проверяется условие первого оператора. Если а равно 5 то оно истинно и выполняется блок кода первого оператора, выводится сообщение "Введенное число равно пяти". Если условие ложно, допустим что это 3, то срабатывает оператор else и проверяется условие второго оператора if(a>5). Поскольку и это выражение оказывается ложным, программа переходит к третьему условию if(a<5), которое является истинным, в результате чего появляется сообщение "Введенное число меньше пяти", что и соответствует действительности. switch Давайте теперь представим, что в предложенном выше примере нам необходимо обработать не три варианта, а все десять, сообщая при этом чему равно введенное число. В таком количестве операторов и скобок можно запутаться. Code
if(a==0)
cout<<"Введенное число равно 0";
else
{
if(a==1)
cout<<"Введенное число равно 1 ";
else
{
if(a==2)
cout<<"Введенное число равно 2 ";
else
{
if(a==3)
cout<<"Введенное число равно 3 ";
else
{
if(a==4)
cout<<"Введенное число равно 4 ";
else
{
if(a==5)
cout<<"Введенное число равно 5 ";
else
{
if(a==6)
cout<<"Введенное число равно 6 ";
else
{
if(a==7)
cout<<"Введенное число равно 7 ";
else
{
if(a==8)
cout<<"Введенное число равно 8 ";
else
{
if(a==9)
cout<<"Введенное число равно 9 ";
else
{
if(a==10)
cout<<"Введенное число равно 10 ";
}
}
}
}
}
}
}
}
}
}
Ужас, правда. Для упрощения обработки таких вот однотипных условий, когда проверяются различные варианты одной переменной, используется оператор выбора – switch.
Вот так будет выглядеть предыдущий пример с использованием оператора switch: Code
switch (a)
{
case 0: cout<<"Введенное число равно 0"; break;
case 1: cout<<"Введенное число равно 1"; break;
case 2: cout<<"Введенное число равно 2"; break;
case 3: cout<<"Введенное число равно 3"; break;
case 4: cout<<"Введенное число равно 4"; break;
case 5: cout<<"Введенное число равно 5"; break;
case 6: cout<<"Введенное число равно 6"; break;
case 7: cout<<"Введенное число равно 7"; break;
case 8: cout<<"Введенное число равно 8"; break;
case 9: cout<<"Введенное число равно 9"; break;
case 10: cout<<"Введенное число равно 10"; break;
}
Разницу чувствуете) Вот его синтаксис: Code
switch (Переменная)
{
case Значение 1: Блок кода; break;
case Значение 2:
Блок кода;
break;
…
default:
Блок кода;
}
Оператор switch поочередно сравнивает переданное ему значение Переменной со стоящим после оператора case значением. Если оно идентично, то выполняется соответствующий блок кода. После чего срабатывает оператор break, который прекращает работу оператора выбора. Если случайно забыть поставить break, то программа продолжит сравнивать значения, даром тратя время.
Если необходимое значение не найдено, то выполняется блок кода заданный по умолчанию, то есть стоящий после оператора default. Кстати, если значение по умолчанию не нужно, то default можно и не задавать.
Есть еще одна особенность оператора выбора, связанная с использованием оператора break. Допустим, что вам необходимо чтобы в двух или больше ситуациях был выполнен один блок кода. В этом случае используется такой синтаксис:
Code
switch (Переменная)
{
case Значение 1:
case Значение 2: Блок кода; break;
}
Здесь после первого значения отсутствует break, а это означает что
Будут выполнены для обоих значений. Условный оператор Ну и напоследок говоря об операторах ветвления нельзя не упомянуть условный оператор - ?:. По сути это сокращенная запись того же if else.
Вот его синтаксис: Code
(Условие) ? Выражение 1 : Выражение 2
Ключевыми в приведенной выше строке есть вопросительный знак и двоеточие. А работает оператор так. Сначала вычисляется условие, если оно истинно то срабатывает выражение 1, если условие ложно, то выполняется выражение 2.
Особенностью условного оператора есть то, что выражения должно быть коротким, и весь оператор не должен разбиваться на несколько строк. При этом, в отличии от предыдущих операторов ветвления, условный оператор можно применять в самых неожиданных местах внутри кода. При необходимости я это продемонстрирую, а сейчас просто приведу небольшой пример. Code
X = (I > 5) ? 20 : 40;
Если I больше 5, то Х будет присвоено 20, во всех остальных случаях 40.
Вот так бы выглядел этот пример с использованием if. Code
if(I > 5)
{
X =20;
}
else
{
X =40;
}
Теперь, на конец хотелось бы сделать небольшое пояснение относительно терминологии. Я использовал три термина: оператор ветвления для if else, оператор выбора для switch и условный оператор для ?:. Так вот, в разной литературе любым из этих терминов может называться любой из перечисленный операторов. Вот такое дело. Я так и не смог определится, кому принадлежит конкретный термин. Далее по тексту я буду использовать приведенные названия применительно к каждому конкретному оператору.
На этом знакомство с операторами ветвления закончено. Теперь мы можем внести изменения в нашу первую игру. Корректируем «Осаду».
Открываем в студии проект с игрой осада и переходим к исходному коду. Как это сделать вы должны уже знать с первого урока. Находим там такие строки: Code
// Вывод результата вместе с условиями выиграша
cout << "У противника осталось " << Draco << " Драконов,"
<< Golem << " Големов, "<< Arrows << " Лучников, "<< Peasant <<
" Крестьян\n." << "Если войска остались - ВЫ ПРОИГРАЛИ";
Именно здесь нам необходимо внести соответствующие изменения, чтобы победителя выбрала программа. Делается это следующим образом. Удаляем из предыдущей строки Code
<< "Если войска остались - ВЫ ПРОИГРАЛИ"
Поставив вместо нее изученный оператор ветвления. Code
if(Draco==0&&Golem==0&&Arrows==0&&Peasant==0) // проверка результата боя
{
cout << "ВЫ ОДЕРЖАЛИ ДОБЛЕСНУЮ ПОБЕДУ";
}
else
{
cout << "ВЫ ПОЛУЧИЛИ СОКРУШИТЕЛЬНОЕ ПОРАЖЕНИЕ";
}
Как мы видим здесь, в первой строчке выполняется проверка равно ли количество оставшихся войск нолю. Делается это с помощью операторов сравнения и логического оператора И. Напомню, что согласно приоритета сразу проверяется равенство, а после начинает свою работу оператор &&. Если условие истинно, то выводится сообщение о победе, а если ложно – о поражении.
Теперь вы можете откомпилировать измененную программу и, если вы не допустили ошибки, программа заработает и в конце вам будет конкретно указано победили вы или проиграли.
Вот код всей программы: Code
#include <iostream>
using namespace std;
int main( void ) // главная функция программы
{
setlocale( LC_ALL, "Russian" ); // задействование русского языка
int Draco=2; // переменная для Дракона
int Golem=4; // голем
int Arrows=3; // лучник
int Peasant=1; // крестьянин
int i=0; // переменная для хранения введенного игроком числа
// Вывод вступительного текста
cout << "После долгого, долгого перехода вы наконец-то добрались к окресностям форта,\n";
cout << "который приказом короля вам велено захватить.\n";
cout << "Но, как выяснилось, форт хорошо охраняется:\n\n";
cout << "Южные ворота охраняет Дракон.\n";
cout << "Северную стену - Голем.\n";
cout << "На восточной расположились лучники,\n" ;
cout << "а на западной - крестьяне.\n\n";
cout << "Ваша армия состоит из\n";
cout << "1. Асасинов\n";
cout << "2. Магов\n";
cout << "3. Латников\n";
cout << "4. Катапульты\n\n";
cout << "(Для выбора вариант ответа вводите соответствующий номер и нажимаете ENTER.\n";
cout << "Выбрать войска можно только один раз.)\n\n";
cout << "Кого вы отправите против Дракона?\n";
cin >> i; // получение данных от игрока
Draco = Draco - i; // вычисление результата для Дракона
cout << "Кого вы отправите против Голема?\n";
cin >> i; // получение данных от игрока
Golem = Golem - i; // вычисление результата для Голема
cout << "Кого вы отправите против лучников?\n";
cin >> i; // получение данных от игрока
Arrows = Arrows - i; // вычисление результата для Лучников
cout << "Кого вы отправите против крестьян?\n";
cin >> i; // получение данных от игрока
Peasant = Peasant - i; // вычисление результата для Крестьян
// Вывод результата вместе с условиями выиграша
cout << "У противника осталось " << Draco << " Драконов,"
<< Golem << " Големов, "<< Arrows << " Лучников, "<< Peasant <<
" Крестьян\n\n";
if(Draco==0&&Golem==0&&Arrows==0&&Peasant==0) // проверка результата боя
{
cout << "ВЫ ОДЕРЖАЛИ ДОБЛЕСНУЮ ПОБЕДУ";
}
else
{
cout << "ВЫ ПОЛУЧИЛИ СОКРУШИТЕЛЬНОЕ ПОРАЖЕНИЕ";
}
cin.get(); // ожидание нажатия клавиши
cin.get(); // ожидание нажатия клавиши
return 0; // возвращение значения, и завершение программы
}
Windmill 2
WindMill 2D Game Engine
|
|
|
| |
| nilrem | Дата: Пятница, 11 Сентября 2009, 19:00 | Сообщение # 5 |
|
Просветленный разум
Сейчас нет на сайте
| 2. Оформление кода Теперь немного отвлечемся от программирования и поговорим о правилах оформления исходного кода. Конечно, никто не запрещает вам писать все как вам вздумается, но сомневаюсь, что через несколько дней сможете без труда разобраться в том, что понаписывали.
Тогда как грамотно оформленная программа имеет отличную читабельность, ее легко исправлять и модифицировать. Сейчас в этой программе чуть больше 60 строк, а что вы будете делать, если их станет намного больше. Например в моем движке этих самых строк около 30 тысяч, и это ведь еще даже и не половина. Отступы
Итак начнем. Первое очень нам нужно узнать, и на что вы уже возможно обратили внимание, это отступы. Вот несколько рекомендаций:
Отступы в строках необходимо располагать так, чтобы логически связанные блоки кода выглядели единой группой.
Между этими группами можно оставлять пустую строку. Кроме того эту группу можно выделить, заключив ее в фигурные скобки.
При этом открывающую и закрывающую скобку нужно располагать в отдельных строках и на одной линии по вертикали, то есть друг под другом.
Все вложенные блоки кода, например в операторе ветвления необходимо писать с отступом, при этом, на каждый новый уровень вложения нужно добавляться новый отступ.
Все, что я здесь описал вы могли видеть в приведенных ранее примерах кода. Кроме того Среда разработки будет вам в этом всячески помогать. Главное при этом ей не мешать. Комментарии
О комментария мы уже говорили, но хотелось бы дать еще несколько советов:
Самое важное – комментарий должен быть наиболее содержательным, чтобы и через неделю и через год вы смогли понять что он означает и разобраться в коде.
Избегайте избыточного комментирования, используйте их только если это действительно нужно.
Например: Code
a=5; // присвоение переменной а значения 5
Этот комментарий, хоть и отображает суть кода, но совершенно не нужен, ибо из кода и так все понятно. К тому же в данном случае на написание комментария будет затрачено намного больше времени, чем на сам код. Именование переменных
Ну и поговорим немного об именах переменных. О том, какие они должны быть, я уже рассказывал. Теперь я поведаю о касающемся этой темы стандарте, получившей название Венгерская нотация. Многое в ней вам будет еще не понятно, но я не решился разбивать ее на части. Да к тому же пользоваться этим соглашением или нет, решать вам. Я так и не смог себя приучить к некоторым положениям этой нотации. Вот текст документа:
Соглашение об идентификаторах в программе.
Данный документ предназначен для изложения основных достоинств о формальном формировании идентификаторов.
При введении нового идентификатора в программу, хороший программист учитывает следующие факторы:
1. мнемоническое значение: идентификатор должен легко запоминаться
2. смысловое значение: роль идентификатора должна быть ясна из его названия
3. преемственность: часто рассматривается как чисто эстетическая идея, но все же, похожие объекты должны иметь похожие идентификаторы.
4. скорость решения: придумывание, ввод и редактирование идентификатора не должны занимать слишком много времени, идентификатор не должен быть слишком длинным.
Выбор имен может стать задачей, поглощающей лишнее время у разработчика. Часто идентификатор, удовлетворяющий одним условиям противоречит другим. Кроме того, поддержать преемственность имен иногда бывает достаточно трудно.
Преимущества Соглашений
Данные соглашения об идентификаторах обеспечивают удобную технологию для формирования имен, удовлетворяющих вышеупомянутым критериям. Основной идеей является передача основных характеристик идентификатора как части в его названии. Эта простая идея, безусловно, требует уточнения (что, например, предполагается под "критерием", что делать если они(критерии) не уникальны?). Однако, давайте сначала оговорим общие положения.
Названия будут мнемоническими в строго определенном смысле: идентификатор будет очевиден для того, кто помнит название характеристики или принцип его построения.
Названия имеют смысловое значение: должна быть возможность отобразить любое название в наборе характеристик.
Названия будут непротиворечивы, так как произведены теми же самыми правилами.
Построение названий будет производится механически, следовательно быстро.
Выражения в программе могут быть проверены на преемственность методами, похожими на обычные измерения свойств объекта.
Правила обозначения
Предлагаются следующие правила обозначения:
1) Описание характеристики идентификатора входит в идентификатор. Удобной пунктуацией является указание характеристики перед названием, с разделением их (началом названия с большой буквы в Cи, например: rowFirst: row - характеристика, Fist - название).
2) Название отличают идентификаторы, имеющие один и тот же тип и существующие в одном контексте. Контекстом может являться как система в целом, так и блок, процедура, структура данных в зависимости от среды программирования. Если существует стандартное название, оно должно быть использовано. Выбор должен быть максимально простым, так как требуется уникальность идентификатора только в пределах определенного контекста.
3) Простые типы названы короткими тегами, которые выбраны программистом. Такие теги должны быть интуитивно понятны большинству программистов.
Тег должен быть коротким для выполнения четвертого условия (фактора), введенного нами выше. Названия составных типов должны включать имена составляющих. Существуют стандартные схемы построения указателя и массива. Другие типы данных могут быть определены произвольно. Например префикс p используется для указателей. В принципе, соглашения могут быть обогащены в соответствии с новыми схемами типов данных. Однако стандартные конструкции могут послужить еще долгое время. Следует отметить что поля структур не должны участвовать в формировании префикса, так как в этом случае конструкции более чем с двумя полями были бы просто не читаемыми. Более важна передача в префиксе для структуры ее сути, зависимой не от набора полей, а от способа ее использования.
Я рекомендую использование нового тега для каждой новой структуры данных. Тег с некоторой пунктуацией (первая или все заглавные буквы) тоже может и должен использоваться как имя типа для структуры. Использование новых тегов так же оправдано в тех случаях, когда это влияет на удобочитаемость программы.
Мой опыт показывает, что теги более трудны для выбора по сравнению с названиями. Когда необходим новый тег, первым желанием бывает использовать короткий, наглядный, общий и универсальный термин как имя типа. Это - почти всегда ошибка. Нельзя резервировать наиболее полезные термины и фразы для частных целей конкретной задачи или даже версии. Как правило любой универсальный термин одинаково применим ко многим типам, даже в той же самой программе.
Обратите внимание, что, как правило, очевидный выбор для названия, является и самым правильным. Причиной этому является то, что название должно быть уникально в рамках значительно меньшего по сравнению с тегом контекста. Так как названия, как правило, не участвуют в формировании других названий, им не требуется быть особенно короткими.
Например мы создаем графическую программу. В данном случае у нас существует тип данных "цвет". Естественным желанием является сделать префикс color для обозначения цвета. Однако при детальном рассмотрении может оказаться, что применение термина color более удобно в приложении к названию, например: LineColor. Для обозначения цвета более выгодным является сокращение, например clr. clrDefault.
Обозначение для упрощения написания.
Правильное формирование идентификаторов должно позволить нескольким программистам независимо создавать программу для решения одной задачи. Каждый программист должен знать правила именования, иначе будет невозможно организовать взаимодействие. Такой эксперимент бесполезен при рассмотрении крупного проекта, однако представляет из себя четкую цель. Результатом является возможность понимать и исправлять программу, написанную другим человеком. Такой результат достижим при надлежащем использовании общеопределенных соглашений. Именно поэтому процесс документирования тегов крайне важен.
Обозначение для процедур.
К сожалению, простое понятие квалифицированных напечатанных тэгов не работает для названий процедуры. Некоторые процедуры не получают параметров или не возвращают значения. Контексты названий процедур имеют тенденцию быть большими. Следующий набор специальных правил для процедур может работать весьма удовлетворительно:
1) Названия процедур должны отличаться от других названий пунктуацией, например, всегда начинаясь с заглавной буквы (тогда как тэги характеристик других идентификаторов пишутся строчными буквами).
2) Начинайте название процедуры с тега типа возвращаемого значения, если таковое существует.
3) Выразите действие процедуры в одном или двух словах. Слова должны быть разделены пунктуацией для более простого разбора читателем (обычный метод заключается в использовании заглавных инициалов для каждого слова).
4) В конец названия можно добавить список тегов некоторых или всех формальных параметров, если есть смысл.
Последний пункт противоречит более ранним замечаниям по описанию структуры данных. Если параметры процедуры будут изменены, то это повлечет за собой изменение имени и всех точек вызова процедуры. Однако такое изменение может быть использовано для проверки того, что все точки вызова измененной процедуры будут также выполнены корректно. В случае же со структурами данных, добавление или изменение поля не оказывает решающего влияния на использование типа данных. В случае если процедура имеет один или два параметра использование тегов упростит выбор имени.
1. Некоторые примеры для названий процедуры
Описание Название
InitSy Берет sy как его параметр и инициализирует его.
OpenFn fn - параметр. Процедура "откроет" fn. Никакое значение не будет возвращено.
FcFromBnRn Возвращает fc, для переданной пары Bn,Rn (Названия не передают нам информации о типе данных для Fc, Rn, Bn).
Далее приведен список стандартных конструкций, X и Y замещают произвольные теги. 2. Стандартные конструкции типа
pX Указатель на X.
dX Различие между двумя образцами типа X. X + dX имеет тип X.
cX Индекс образцов типа X.
mpXY Массив Ys, индексированного по X.
rgX Массив Xs.
iX Индекс массива rgX.
grpX Группа Xs, сохраненных последовательно. Используется когда X элементы имеют переменный размер и не применима стандартная индексация. Элементы X индексируются способом, отличным от обычного.
bX относительное смещение к типу X. Используется для обращений к полям переменной длины в структурах. Смещение может быть указано в байтах или словах, в зависимости от вида индексации.
cbX Размер X в байтах.
cwX Размер X в словах.
C конструкциями такого типа существует одна проблема. Например, является ли pfc собственно тегом или это указатель на fc. Ответ на такой вопрос может дать только человек, знакомый с принятой в рамках контекста системой именования.
Далее приведены стандартные имена. X замещает любой тег типа, записанный в нижнем регистре. 3. Стандартные спецификаторы
XFirst первый элемент в упорядоченном наборе X
XLast последний элемент в упорядоченном наборе X
XLim строгий верхний предел набора значений X. Границей цикла должно быть X < XLim.
XMax строгий верхний предел набора значений X. Если X начинается с 0, то XMax равен числу различных значений X.
XT временное значение X. 4. Некоторые базовые типы
f Флажок (Булева переменная, логическое значение). Используемое название должно относиться к истинному состоянию. Исключение: константы fTrue и fFalse.
w Машинное слово
ch Символ, обычно в тексте ASCII.
b Байт
sz Указатель на строку терминированную нулем (ASCIZ) 5. Базовые префиксы типов данных Win32
g_ префикс для глобальной переменной
m_ префикс для переменной класса
c константа (префикс для типа) const
l длинный (префикс для типа) far, long
p указатель (префикс для типа) *
ch char char
b байт BYTE, unsinged char
w 16-битное слово (2 байта) WORD, unsigned short
dw 32-битное слово (4 байта) DWORD, unsigned long
n,i целое int
flt с плавающей точкой float
dbl с плавающей точкой double
f логическое BOOL
sz ASCIZ строка char[]
psz ASCIZ строка char *
pcsz константа ASCIZ строка const char *
pv произвольный указатель void *
ppv указатель на произвольный указатель void **
h хендл HANDLE, void *
unk OLE объект IUnknown
punk указатель на OLE объект IUnknown *
disp Automation объект IDispatch
pdisp указатель на Automation объект IDispatch *
Ну вот, Осаду мы усовершенствовали, выучив попутно новый материал. Познакомились с операторами ветвления и правилами оформления кода. Теперь, дабы закрепить эти знания, приступим к написанию еще одной игры. 3. Игра «Лабиринт» Как всегда, начинаем с планирования. Что же именно мы будем делать.
Смысл игры в том, чтобы добраться к выходу из лабиринта. Игровой процесс выглядит так. Перед вами есть план лабиринта, на котором указана ваша позиция. Вводя направление движения вам необходимо дойти к выходу. При этом движение назад или на стену означает попадание в ловушку и как следствие – проигрыш. Как это будет реализовано.
Реализовано это, как и в прошлый раз, будет в виде диалога. Программа сначала выводит небольшое сюжетное введение, а затем последовательно запрашивает у вас данные. Лабиринт разбит на сектора, каждая из которых имеет свой номер. Поскольку нумерация по горизонтали и вертикали одинакова, программа сначала спрашивает направление движения(по горизонтали или по вертикали), а затем номер сектора. От выбора будет зависеть продолжение игры или проигрыш. В случае продолжения лабиринт обновляется, указывая на новую позицию игрока. При выводе текста должны быть подсказки по управлению программой. Что для этого понадобится.
Вот тут я вас обрадую. Все что нужно вы уже знаете. Поэтому вам понадобится только терпение, сообразительность и внимание поскольку программа содержит свыше 400 строк кода. Правда 50 строк, в небольшой вариации, повторяются шесть раз. Приступаем. Вспоминаем первый урок, открываем студию и создаем новый проект, который я назвал labyrinth. Затем добавляем в него файл исходного кода и начинаем писать программу.
Для этого может скопировать исходный код из нашей игры «Осада», и удалить оттуда, из главной функции main все, кроме строчки Code
setlocale( LC_ALL, "Russian" );
Она нам еще понадобится.
Далее объявляем четыре переменные: Code
int i; // переменная для направления
int num; // номер сектора
bool GameOver = false; // эта переменная сигнализирует о проигрыше.
int goRes; // вариант проигрыша
Первые две используются для получения данных при вводе. Вторая, логическая переменная GameOver, меняет свое значение в случае возникновения проигрышной ситуации. Переменной сразу же присваивается значение. В принципе в данном случае этого можно и не делать, поскольку при его отсутствии, переменная все равно считается ложной. Как только она становится истинной весь дальнейший код начинает игнорироваться.
В переменной goRes будет содержатся информация о способе проигрыша. Может он произошел в результате введения некорректных данных, может вы попали в ловушку и т.д.
После переменных выводится небольшое сюжетное введение, дается пояснение по управлению программой и выводится план лабиринта. Я не буду это здесь иллюстрировать, можете посмотреть дальше в коде всей программы.
Перемещение по лабиринту происходит в виде последовательных шагов. Далее в коде идет основная конструкция нашей программы, в которой производится обработка каждого шага: Code
// Шаг № 1
if(!GameOver)
{
// Ввод информации о перемещении
cout << "Как вы будете двигаться, по горизонтали[Введите 1] или по вертикали[2]?\n";
cin >> i;
cout << "Укажите номер сектора, куда вы желаете переместится?\n";
cin >> num;
if(i == 1) //Если движение по горизонтали
{
switch(num) //обработка номера сектора
{
case 1:
goRes = 6;
GameOver = true;
break;
case 2:
case 3:
goRes = 4;
GameOver = true;
break;
default: // значение по умолчанию, если введено некорректное значение
goRes = 2;
GameOver = true;
}
}
else
{
if(i == 2) //Если движение по вертикали
{
switch(num) //обработка номера сектора
{
case 1:
case 3:
goRes = 5;
GameOver = true;
break;
case 2:
cout << "\nВы благополучно продвинулись вперед по подземелью\n";
cout << " ____ \n";
cout << "3| | |\n";
cout << "2|0|___|\n";
cout << "1|_____|\n";
cout << " 1 2 3\n";
break;
default: // значение по умолчанию, если введено некорректное значение
goRes = 2;
GameOver = true;
}
}
else // если введено некорректное значение
{
goRes = 1;
GameOver = true;
}
}
}
В самом начале находится оператор ветвления, который проверяет состояние переменной GameOver. Дальнейший код мог бы исполняться, только если условие истинно. Тогда как переменная GameOver ложная. Поставленный логический оператор !(НЕ) и превращает ложь в правду.
Вообще-то в первом шаге эта проверка не нужна, но чтобы в дальнейшем иметь возможность просто скопировать эти строки дальше, я и поставил его с самого начала. Ведь правильной работе он не мешает.
После проверки, происходит ввод информации и присвоение ее соответствующим переменным. Далее с помощью все того же оператора ветвления происходит проверка первой переменной – i для направления движения, и выполняется соответствующий блок кода для конкретной сектора. Эта проверка построена по уже знакомому принципу, последующая проверка производится только если первое условие ложное. Также обрабатывается и вариант, когда оба условия не правильные, то есть если введено некорректное значение.
Проверка сектора производится с помощью оператора switch. Code
switch(num) //обработка номера сектора
{
case 1:
goRes = 6;
GameOver = true;
break;
case 2:
case 3:
goRes = 4;
GameOver = true;
break;
default: // значение по умолчанию, если введено некорректное значение
goRes = 2;
GameOver = true;
}
В зависимости от введенного номера и текущей ситуации, то есть положения в лабиринте, в операторе case происходят действия определения проигрыша. Если эта проигрышная ситуация возникает то переменной GameOver присваивается значение true, а переменной goRes значение варианта проигрыша. А если введенные данные некорректные, то в этом случае срабатывает вариант по умолчанию.
И только один вариант должен быть правильным. В этом случае программа выводит подтверждение о правильности хода, и обновленный план лабиринта с изменившейся позицией игрока:
Code
case 2:
cout << "\nВы благополучно продвинулись вперед по подземелью\n";
cout << " ____ \n";
cout << "3| | |\n";
cout << "2|0|___|\n";
cout << "1|_____|\n";
cout << " 1 2 3\n";
break;
С кодом одного шага разобрались, теперь необходимо его размножить и внести изменения, соответствующие правильному движению по лабиринту. У меня это шесть шагов.
После совершения всех шагов находится код вывода результата: Code if(GameOver)
{
switch (goRes)
{
case 1:
cout << "\nВы выбрали иное направление, и попытались проломить головой пол,\n"
<< "если бы у вас были мозги, то они бы растеклись по полу\n";
break;
case 2:
cout << "\nБлин, вы цифры знаете, или со зрением проблемы.\n"
<< "Вобщем, вы достали из ножен свой топор и им застрелились.\n";
break;
case 3:
cout << "\nВы сделали неосторожный шаг назад \n"
<< "и свалились в бездонную пропасть.\n";
break;
case 4:
cout << "\nВы попали в ловушку\n"
<< "Расколов каменный пол, стальные колья пронзили ваши тела\n";
break;
case 5:
cout << "\nВы попали в ловушку\n"
<< "Зловонная жижа заполнила коридор. Вы захлебнулись\n";
break;
case 6:
cout << "\nВы попали в ловушку\n"
<< "Стены подземелья сомкнулись, растерев вас в пыль\n";
break;
}
cout << "\nВ темных закоулках страшного подземелья вас подстерегла смерть.\n"
<< "ВЫ ПРОИГРАЛИ!\n";
}
else
{
cout << "\nНу вот и свет в конце тонеля. Вы вышли из лабиринта. Поздравляю.\n"
<< "ПОБЕДА!\n";
}
Здесь вновь проверяется переменная GameOver. Но на этот раз в ее настоящем значении, без логического оператора. Если ее значение – истина, то это означает, что в игре возникла ситуация, когда игрок проиграл. Поэтому дальше производится проверка переменной и вывод соответствующего ей значения.
Code
switch (goRes)
{
case 1:
cout << "\nВы выбрали иное направление, и попытались проломить головой пол,\n"
<< "если бы у вас были мозги, то они бы растеклись по полу\n";
break;
case 2:
cout << "\nБлин, вы цифры знаете, или со зрением проблемы.\n"
<< "Вобщем, вы достали из ножен свой топор и им застрелились.\n";
break;
case 3:
cout << "\nВы сделали неосторожный шаг назад \n"
<< "и свалились в бездонную пропасть.\n";
break;
case 4:
cout << "\nВы попали в ловушку\n"
<< "Расколов каменный пол, стальные колья пронзили ваши тела\n";
break;
case 5:
cout << "\nВы попали в ловушку\n"
<< "Зловонная жижа заполнила коридор. Вы захлебнулись\n";
break;
case 6:
cout << "\nВы попали в ловушку\n"
<< "Стены подземелья сомкнулись, растерев вас в пыль\n";
break;
}
Конечно, можно было сделать вывод этих сообщений в том месте кода, где мы присваивали переменной goRes значение. Но в таком случае размер программы стал бы значительно больше, контролировать ее стало бы труднее. Да и появись в тексте сообщения ошибка, ее бы пришлось править везде, а так только в одном месте.
После вывода это сообщения программа выводит еще одно, финальное:
Code
cout << "\nВ темных закоулках страшного подземелья вас подстерегла смерть.\n"
<< "ВЫ ПРОИГРАЛИ!\n";
Это в случае проигрыша. А если вы выиграли то: Code
else
{
cout << "\nНу вот и свет в конце тонеля. Вы вышли из лабиринта. Поздравляю.\n"
<< "ПОБЕДА!\n";
}
Ну а завершают нашу программу уже знакомые: Code
cin.get(); // ожидание нажатия клавиши
cin.get(); // ожидание нажатия клавиши
return 0; // возвращение значения, и завершение программы
Windmill 2
WindMill 2D Game Engine
|
|
|
| |
| nilrem | Дата: Пятница, 11 Сентября 2009, 19:05 | Сообщение # 6 |
|
Просветленный разум
Сейчас нет на сайте
| 4. Послесловие
Еще один урок позади. С практической точки зрения он был намного сложнее. Но я надеюсь, что у вас все получилось. А если возникли какие-то проблемы – обращайтесь, спрашивайте. Я всегда готов помочь. Но напоминаю, вопросы задавать только в рамках этого курса.
К этой лекции прикреплены файлы проектов с обеими играми: модифицированной «Осадой» и «Лабиринтом». Но я бы порекомендовал вам набрать все самостоятельно. Конечно, объем кода в лабиринте для начинающего может показаться огромным. Но ведь чем больше практики, тем быстрее прогресс. Страуструп, автор языка С++, говорил что программист хорошо изучит только те аспекты языка программирования, которые чаще всего использует. Ну это и так понятно.
Кроме того, возможно, что на форуме программистов не очень много, тогда как на получившиеся игры наверное хотели бы посмотреть все. Поэтому выкладываю ссылки на екзешники:
Осада – http://fabermun.at.ua/cpp/siege.rar
Лабиринт - http://fabermun.at.ua/cpp/labyrinth.rar
На этом все.
До встречи.
Windmill 2
WindMill 2D Game Engine
|
|
|
| |
| nilrem | Дата: Пятница, 11 Сентября 2009, 19:11 | Сообщение # 7 |
|
Просветленный разум
Сейчас нет на сайте
| Статья 3: Повторение – мать учения. Здравствуйте. Не волнуйтесь. Специально возвращаться к ранее изученному материалу нам не придется, поскольку и так в каждом последующем уроке мы будем использовать все, что выучили раньше. А как же иначе. Все что я вам рассказываю это самые основы, стержень языка, который наличествует в программе любой сложности. А повторение я упомянул по той причине, что сейчас мы будем учить способ, с помощью которого в языке C++ можно многократно, циклически выполнять одни и те же действия. Например, в прошлом уроке один блок кода выполнялся шесть раз. Этого можно было избежать, если бы вы были знакомы с методами организации циклов. 1. Ин и Де
Сначала я хочу вас познакомить с двумя арифметическими операторами, имеющими очень важное значение для циклов. Это такие вот интересные конструкции ++ - двойной плюс, который называют инкремента и -- двойной минус – декремента. Суть работы этих операторов очень простая. Первый повышает значение переменной на единицу, а второй уменьшает. Code
А = 5;
А++; // А станет равно шести
А--; // А вновь станет равно пяти
Эта запись аналогична следующей: Code
А = 5;
А = А + 1; // А станет равно шести
А = А - 1; // А вновь станет равно пяти
И результат работы обеих примеров идентичный. Просто использование инкременты и декременты проще. Но есть еще одна особенность. Эти операторы могут находится не только после, но и до переменной Подобный вариант записи операторов называется префиксным, тогда как предыдущий - постфиксным.
Результат работы обоих вариантов идентичный, а вот способ этой самой работы кардинально отличается
Если в выражении встречается инкремента или декремента в префиксной записи, то есть перед переменной, то значение переменной сразу уменьшается или увеличивается на единицу. Если запись постфиксная, то сначала выражение вычисляется полностью, игнорируя инкременту/декременту, и только затем эта переменная увеличивается или уменьшается на единицу.
Чтобы лучше это понять приведу соответствующий пример: Code
int x=1, y;
y=(x++) * 5;
Здесь сначала х умножится на пять, значение будет присвоено у, а затем сработает инкремента и х увеличится на единицу. В результате у == 5, х == 2.
Обратите внимание на использование скобок. Если этого не сделать, то компилятор потеряется в нагромождении операторов. Про ошибку он не скажет, но вот результат будет непредсказуемый.
Ну и пример для префиксной записи: Code
int x=1, y;
y=(++x) * 5;
В этом случае сначала х будет увеличен, а затем умножен на 5. В результате у == 10, х == 2. Надеюсь, что вам все понятно.
Кроме того как эти операторы работают, необходимо знать что префиксная их запись работает быстрее чем постфиксная. И вот почему: Когда при выполнении программы с этой строкой доходит очередь до инкременты, создается временная переменная, в которую записывается новое, увеличенное значение х. А потом, после вычисления выражения значение временной переменной обратно присваивается х. Естественно на все это тратится лишнее время. Чисто теоретически это выглядит так: Code
int temp; // создается временная переменная
temp=x+1; // ей присваивается увеличенный х, при этом сам х не меняется.
y=x*5; // х умножается 5, результат присваивается у
x=temp; // х присваивается значение временной переменной
Конечно, если оператор выполняется всего один раз, то затраты времени не ощутимы, а вот если это где-то в цикле повторяется несколько сотен а то и тысяч раз, то это уже совсем другое дело. Раз мы уже упомянули способы упрощения и улучшения кода, расскажу вам еще и о вариантах оператора присвоения.
Запись: Можно упростить так: Оба примера имеют идентичный результат работы
Подобная комбинация арифметического оператора с оператором присваивания называется составным присваиванием.
Составное присваивание допустимо для большинства арифметических операторов.
Кроме плюса также можно использовать минус, умножение и деление. Эти записи идентичны следующим: Code
А = А - 5;
А = А * 10;
А = А / 3;
2. Циклы
В языке с ++ есть несколько способов организации циклов.
Самый простой из них это так называемый цикл с предусловием. while
Как можно понять их названия цикл с предусловием, прежде чем цикл будет выполняться, проверяется некое условие. Вот синтаксис этого цикла: Code
while( условие )
{
Тело цикла
}
Слово while – переводится с английского как "пока", а всю логику цикла можно передать так. Пока условие истинно, блок кода, содержащийся в теле цикла(это такой термин), будет выполнен, и если условие продолжает оставаться истинным, он будет выполнен снова и снова.
Поэтому если необходимо завершить цикл, нужно изменить условие так, чтобы оно стало ложным, ну или оно станет ложным в процессе, или воспользоваться уже знаком нам оператором break.
Вот два примера.
Первый, где меняется условие: Code
#include <iostream>
using namespace std;
void main ()
{
setlocale( LC_ALL, "Russian" );
int i=0; // переменная для подсчета циклов
while(i<100000) // если i меньше 100000, цикл выполняется
{
i++; // счетчик циклов увеличивается на единицу
}
cout<<"Все. Нажмите Enter для выхода..."; // это, чтобы мы знали, что циклы закончились
cin.get();
}
Здесь, как только цикл выполнится определенное количество раз, постепенно увеличивающаяся переменная изменит условие продолжения цикла, и он больше не будет выполняться. Второй, с использованием оператора break: Code
#include <iostream>
using namespace std;
void main ()
{
setlocale( LC_ALL, "Russian" );
int i=0; // переменная для подсчета циклов
while(true) // бесконечный цикл
{
if (i==100000) // если выполнено 100000 циклов
break; // цикл прерывается
i++; // иначе счетчик циклов увеличивается на единицу
}
cout<<"Все. Нажмите Enter для выхода..."; // это, чтобы мы знали, что циклы закончились
cin.get();
}
ПОДОБНЫЙ СПОСОБ ЗАВЕРШЕНИЯ ЦИКЛА Я НЕ РЕКОМЕНДУЮ. Лучше опираться только на условие, иначе чревато разного рода неприятностями. В последнем примере также продемонстрирован способ организации бесконечного цикла: Здесь условие уже определено как истинное, и изменить его невозможно, следовательно выйти из этого цикла можно только с помощью break или return, но последняя инструкция вообще завершит работу программы. do…while У цикла с предусловием есть брат, которого называют цикл с постусловием. Отличаются они тем, что в цикле с предусловием это самое условие проверяется с самого начала, и если оно ложно, цикл выполняться не будет вообще, тогда как проверка условия в цикле с постусловием происходит только после его первого выполнения. То есть, в не зависимости от условия, цикл будет выполнен как минимум один раз. Бывают моменты, когда подобное необходимо. Во всем остальном эти циклы идентичны.
Вот синтаксис: Code
do
{
Тело цикла
}
while(условие);
Обратите внимание. Здесь после обязательно ставится точка с запятой, тогда как в предыдущем варианте ее не было. Если ее не поставить, компилятор сообщит об ошибке. for Приводя примеры для предыдущих циклов, я использовал в программе счетчики. Следующий способ организации цикла уже предполагает подобного счетчика. Если предыдущие циклы могли выполнятся неопределенное количество раз, то в цикле с использованием оператора for количество повторений задается с самого начала. Кстати, именно этому циклу отдает предпочтение большинство программистов. Синтаксис таков: Code
for(инициализация счетчиков; условие; увеличение счетчика)
{
Тело цикла
}
Как видно непосредственно в операторе for происходит инициализация счетчика, там же выполняется проверка условия, и там же происходит увеличение счетчика. Все собрано в одном месте, что, несомненно, очень удобно.
Этот синтаксис можно заменить аналогичной записью цикла while: Code
инициализация счетчиков
while( условие )
{
{
Тело цикла
}
увеличение счетчика
}
И подобный вариант уже был проиллюстрирован в примере.
А теперь приведу пример, чтобы лучше понять цикл for: Code
#include <iostream>
using namespace std;
void main ()
{
setlocale( LC_ALL, "Russian" );
for(int i=0;i<20;i++)
{
cout<<i<<"\n"; // вывод значения счетчика
}
cout<<"Все. Нажмите Enter для выхода..."; // это, чтобы мы знали, что циклы закончились
cin.get();
}
Опишу как этот пример работает.
В операторе for в месте для инициализации объявляется переменная i, которой сразу же присваивается начальное значение 0. Эта часть цикла будет выполнена только один раз. Далее происходит проверка условия, в данном случае это i<20. В данный момент оно истинно, поэтому выполняется тело цикла со следующим кодом: Code
cout<<i<<"\n"; // вывод значения счетчика
здесь просто выводится текущее значение счетчика.
После этого выполняется последняя часть оператора for, в которой значение счетчика увеличивается на единицу. Далее вновь проверяется условие и если оно по-прежнему истинно – все повторяется. Отмечу, что как в случае с while, условие в цикле for не обязательно должно относится к счетчикам.
Как и с оператором while, с оператором for также возможна организация бесконечного цикла. Для этого достаточно оставить все поля пустыми: Code
for(;;)
{
Тело цикла
}
При работе с циклом for используется еще один оператор – continue.
С английского переводится - "продолжить", и делает он то же, что и означает.
Как только в теле цикла встречается этот оператор, оставшийся код пропускается и программа переходит к оператору увеличения счетчика.
Приведу пример: Code
for(int i=0;i<4;i++)
{
if(i==2) // если i равно 2
continue; // срабатывает этот оператор
cout<<i<<"\n"; // вывод значения счетчика
}
Здесь, когда i станет равно 2, сработает оператор continue, в результате чего строка Code
cout<<i<<"\n"; // вывод значения счетчика
будет опущена, и цикл начнется заново с увеличенным на единицу значением i. Это если условие не станет ложным. Я продемонстрировал вам способы организации бесконечных циклов, но знайте, что нужно быть очень внимательным, чтобы такой вот бесконечный цикл не возник сам по себе. Это часто встречающийся баг, когда программа уходит сама в себя войдя в цикл и не найдя с него выхода. Ну и напоследок отмечу, что все циклы взаимозаменяемы. Просто в одном месте удобнее использовать while, а в другом for. Ну и от личных пристрастий программистов это тоже сильно зависит.
Windmill 2
WindMill 2D Game Engine
|
|
|
| |
| nilrem | Дата: Воскресенье, 04 Октября 2009, 09:23 | Сообщение # 8 |
|
Просветленный разум
Сейчас нет на сайте
| 3. Игра «Угадай число» Возможно после предыдущего урока, после Лабиринта, эта игра покажется вам слишком простой, ведь она в десять раз меньше по объему кода. Но если бы мы на прошлом уроке знали то, что знаем сейчас, то и Лабиринт был бы раза в три меньше. После этой игры можете попробовать его переписать с использованием циклов. Итак, как обычно начинаем с планирования: Что же именно мы будем делать.
Сделаем мы простенькую игру. Программа генерирует случайное число, а игроку предстоит его отгадать. Сюжет я предлагаю вам придумать самостоятельно. Если у вас с этим туго, что ж, в данной игре можно обойтись и без сюжета. Как это будет реализовано.
Реализовано это будет в виде диалога. Программа спрашивает, какое число она сгенерировала. Игрок пытается отгадать и вводит свое предположение. Игра проверяет введенные данные и выводит результат, сообщая больше введенное от сгенерированного, меньше или равно. Что для этого понадобится.
Предполагается, что попыток отгадывания будет несколько, поэтому нам необходимо знать, как использовать циклы. С этим мы уже познакомились выше.
Единственное, что нам пока неизвестно – как сделать так, чтобы программа создавала некое случайное число. Об этом я сейчас и расскажу. Генератор псевдослучайных чисел. Для генерации случайных чисел в С++ предусмотрена специальная функция – rand(). Что такое функция, мы поговорим на следующем уроке. А сейчас вы просто следуйте предложенным примерам.
Для того, чтобы использовать ее в своих программах необходимо подключить к исходному коду заголовочный файл stdlib.h. Как это делается я надеюсь, вы помните: Ну и небольшой пример : Code
#include <iostream>
#include <stdlib.h>
using namespace std;
void main()
{
for(int i=0;i<10;i++) // цикл
{
int r = rand(); // генерация случайного числа
cout<<r<<"\n";
}
cin.get();
}
Здесь в строке Code
int r = rand(); // генерация случайного числа
происходит генерация случайного числа с помощью функции rand() и его присвоение переменной r, а затем эта переменная выводится на экран. Поскольку все это происходит в цикле, то этот код выполняется несколько, в данном случае 10, раз. Запустим эту программу, и она выдаст нам столбик из десяти чисел. Затем запустим эту программу повторно. Как это не прискорбно, но в обоих случаях эти столбики будут идентичны.
Все дело в том, что сгенерировать абсолютно случайное число компьютер не может. Функция всего лишь берет некое начальное значение(по умолчанию это единица), производит над ним определенные арифметические действия и выводит нам результат. Затем, при повторной генерации предыдущий результат используется как начальное значение.
Поскольку арифметические действия всегда одинаковые, то и последовательность чисел всегда идентична. Именно поэтому функцию называют генератором псевдослучайных чисел.
Думаю понятно, что для того, чтобы сделать эти числа более случайными, необходимо как то изменить начальное значение, используемое в генерации.
Для этих целей используется функция инициализации генератора Code
srand(начальное значение)
которая это начальное значение и устанавливает.
Все что остается, это сделать это значение случайным.
Замкнутый круг, но выход есть. В качестве начального используют значение системного времени. При запуске программы время каждый раз будет разное, соответственно и результат работы генератора будет неповторим.
Теперь нам осталось узнать, как получить это системное время.
Для этого нам понадобится еще одна функция – time(0), которая выдает время в секундах, ведя отсчет от 1 января 1970 года по текущий момент. Естественно, что это число никогда не повторится. Для использования этой функции необходимо подключить еще один заголовочный файл time.h. Вот код примера: Code
#include <iostream>
#include <stdlib.h>
#include <time.h> // подключение заголовочного файла
using namespace std;
void main()
{
srand(time(0)); // инициализация генератора
for(int i=0;i<10;i++) // цикл
{
int r = rand(); // генерация случайного числа
cout<<r<<"\n";
}
cin.get();
}
Здесь мы видим подключение нового файла, и инициализацию генератора псевдослучайных чисел перед циклом. Казалось бы, правильнее поместить эту инициализацию внутри цикла, тогда каждое число будет еще более случайным. Но это не так. Дело в том, что компьютеры в наше время обладают чудовищной производительностью. Весь цикл займет всего лишь мгновение, соответственно и функция тайм все десять раз передаст в качестве начального значения одно и то же время. В результате все сгенерированные числа будут одинаковыми. Вы можете проверить это, поместив инициализацию внутри цикла.
Теперь нам нужно узнать какие же именно числа способен выдавать rand, то есть узнать диапазон возможных значений. Я и так знаю ответ, но думаю, что интереснее получить эти данные практически, получив в процессе крупицу опыта. Следующая программа это и делает, а как – видно из комментариев: Code
#include <iostream>
#include <stdlib.h>
#include <time.h>
using namespace std;
void main()
{
srand(time(0)); // инициализация генератора
int max, min, r; // переменные для максимального, минимального и случайного
max=min=rand(); // присвоение случайного значение переменным
for(int i=0;i<1000000;i++) // цикл
{
r=rand(); // присвоение переменной r случайного значения
if(r>max) // если r больше имеющегося максимума
max=r; // то оно становится максимумом
if(r<min) // если r меньше минимума
min=r; // то оно становится минимумом
}
// вывод результата
cout<<"min= "<<min;
cout<<"\nmax= "<<max;
cin.get();
}
Запустив эту программу мы узнаем, что минимальное значение равно 0, а максимальное 32767.
Это очень большой разброс значений, тогда как часто необходимо получить число в заранее определенном, и возможно весьма узком диапазоне.
В языке программирования С++ есть один интересный арифметический оператор - %. Этот знакомый значок процента называется деление по модулю или по другому взятие остатка. Из второго названия ясно, что он делает. Допустим, есть такое выражение результат равен 2. Это остаток от целочисленного деления. То есть 20 = (3*6)+2. Здесь тройка ближайший делитель, а оставшаяся двойка и есть результат. Но чтобы стало еще понятнее, я продемонстрирую, как он работает. Не что он делает, а именно как он функционирует. Если не использовать деления по модулю, то выражение приняло бы такой вид: Code
int x=20,y=6,i,res;
i = 20/6;
res = 20-( i * 6 );
Здесь сначала происходит обычное деление 20 на 6. Результат равен 3,3 (3 целых 3 десятых). Поскольку i у нас целочисленная переменная, запомните, что числа вроде 3,3 в ней хранится не смогут, и в результате преобразования типов дробная часть пропадает. Остается только целая часть 3.
Теперь мы множим эту тройку на шесть и то, что получилось, отнимаем от двадцати.
Результат это и будет то, что называют остатком от деления, и это как раз то, что получается при делении по модулю.
Теперь мы знаем, как этот оператор работает, что же нам это дает. А то, что при делении по модулю результат всегда будет меньше делителя как минимум на единицу.
Поэтому поделив таким способом любое случайное число, например, на десять, мы в результате получим число от 0 до 9.
То есть: не зависимо от того что здесь выдаст rand(), х будет присвоено значение от 0 до 9. Так, думаю, немного разобрались. Но что делать, если нам необходимо число не от 0 и до, а например от 50 и до 80. Вот как это вычислить: Code
int min = 50; // начало диапазона
int max = 80; // конец диапазона
int res = min + (rand()%(max-min));
Сначала вычисляется разность между максимумом и минимумом, что равно 30.
Затем в части выражения rand()%(max-min) получаем случайное число в диапазоне от 0 до 30, и прибавляем его к 50 (минимуму в данном случае), получив таким образом число в необходимом диапазоне.
Надеюсь вам все понятно, ибо на этом с генерацией случайных чисел мы закончили и переходим непосредственно к написанию кода игры. «Угадай число»
Теперь зная все что необходимо, написание программы не составит никакого труда.
Вот ее исходный код: Code
#include <iostream>
#include <stdlib.h>
#include <time.h>
using namespace std;
void main()
{
setlocale(LC_ALL,"Rus");
int r, // случайное число
i=-1, // вводимое значение
c=0; // счетчик колличества попыток
srand(time(0)); // инициализация генератора
r=rand()%100; // генерация случайного числа от 0 до 100
cout<<"Программа задумала число от 0 до 100.\nПопробуй угадать!!!\n";
while(r!=i) // цикл
{
// ввод числа
cout<<"Введите число\n";
cin>>i;
// проверка и вывод подсказки
if(i>r)
cout<<"Многовато будить\n";
if(i<r)
cout<<"Однако, маловато\n";
c++; // наращивание счетчика попыток
}
// отображение результата
if(c < 10)
cout << "Молодец, угадал с "<< c <<" попытки";
if(c > 10)
cout << "Ну с "<< c <<" попытки любой угадает";
cin.get();
cin.get();
}
Думаю, вдаваться в детали не нужно, лишь расскажу вкратце, как он работает.
Вначале объявлены три переменные для хранения случайного числа, введенного значения и счетчика, которым тут же и присвоено начальное значения. Для счетчика это начало отсчета – 0, а вот для вводимого это отрицательное значение, чтобы выражение в условии цикла r!=i было истинным. Ведь сгенерированное число всегда положительное.
Далее происходит инициализация генератора и генерация случайного числа. Это случайное число сравнивается в цикле с вводимым значением, и до тех пор, пока они не равны, программа выдает подсказку больше или меньше сгенерированное число от введенного. Каждый цикл происходит наращивание счетчика попыток.
Как только пользователь вводит верное значение, цикл завершается и выводится результат, с указанием количества попыток. Все. 4. Visual Studio. Структура проекта. Мы уже на протяжении трех уроков учимся писать программы. Но до сих пор программы, в прямом смысле этого слова мы так и не увидели. Ведь то, что мы пишем это исходный код. Да он работает так, как задумано. Но программа с точки зрения обычного человека (не программиста) это некий файл, имеющий окончание .ехе, и его можно запускать в не зависимости от студии, и можно поделится им с друзьями, похваставшись своими достижениями.
Я вас обрадую. Такой файл существует, просто вы пока не знаете, а кто-то может уже и знает, где он находится. Сейчас я укажу вам на его месторасположение, заодно рассказав, из каких файлов и папок состоит проект и для чего они предназначены. Я имею в виду не то, как мы видим проект в студии в обозревателе решений, а то как он хранится на диске.
Итак, все свои проекты, если вы конечно ничего не меняли в настройках, студия хранит в папке Мои документы. Надеюсь, что вы знаете где находится эта папка. Если нет, то самое время поискать самому, ибо объяснять, как пользоваться операционной системой я не намерен.
В Моих документах студия создает папку Visual Studio 2008, это если студия 2008 года. Здесь есть несколько папок, в одной из которых – Projects, и хранятся все создаваемые пользователем проекты.
Каждая папка в Projects, это отдельное решение, которое может включать в себя несколько проектов. Поскольку все С++ проекты имеют одинаковую структуру, то объяснять я буду на примере своего проекта seashell, добавленного к этой статье.
Открываем решение sea. Внутри мы видим папки Debug, Release, seashell и файлы sea. sln , sea.suo и sea.ncb.
О Debug и Release. В этих папках, в зависимости от конфигурации решения, и находится необходимый нам ехе файл вместе с промежуточными файлами компоновки - seashell.pdb, seashell.ilk. Думаю стоит немного упомянуть о конфигурации решения. Есть два варианта конфигурации, или по-простому два набора настроек - Debug и Release. Debug используется в процессе разработки и отладки программы, а Release - для более-менее нормально работающей программы, которую предполагается поставлять конечному пользователю. В зависимости от выбранного, ехе файл попадает в соответствующую папку. О конфигурациях мы поговорим, когда будем изучать отладку программы, а сейчас возвращаемся к структуре проекта.
Файл sea. sln содержит информацию о проектах, входящих в решение. Запуск этого файла приводит к старту студии и загрузки всех объединенных в это решение проектов.
В файле sea.suo хранятся настройки решения. seal.ncb содержит данные, необходимые для работы компонента студии Intellisence. Intellisence – это инструмент, облегчающий работу в студии, подсказывая нам существующие названия переменных, функций и операторов, выполняя автозавершение кода и многое другое
В папке seashell хранится все, что относится к конкретному проекту. В ней находятся папки Debug, Release и три файла:
seashell.cpp – файл исходного кода.
seashell.vcproj.user и seashell.vcproj – файлы с настойками проекта.
А в папках Debug, Release, как и в прошлый раз в зависимости от выбранной конфигурации, хранится скомпилированный исходный код с дополнительными файлами.
На этом разбор структуры закончен. Возможно, из-за повторяющихся названий все выглядит немного запутанным, но не волнуйтесь, со временем вы освоитесь, тем более что самое важное что нужно запомнить – где находится этот самый екзешник, а о назначении остальных файлов знать пока не обязательно.
Windmill 2
WindMill 2D Game Engine
|
|
|
| |
| nilrem | Дата: Воскресенье, 04 Октября 2009, 09:31 | Сообщение # 9 |
|
Просветленный разум
Сейчас нет на сайте
| 5. Послесловие.
Конечно, игра «Угадай число» получилась не в пример предыдущей, простая и не очень интересная. Но что мешает вам придумать свой сюжет, добавить функциональности, например, ограничив количество попыток для угадывания. В прикрепленном исходном коде вы можете посмотреть на то, что получилось у меня. Программа хоть и играбельна, но не завершена.
Во-первых, ее необходимо протестировать на работоспособность всех возможных игровых ситуаций.
Второе, в программе отсутствует проверка, хватит ли игроку денег для ставки.
Я предлагаю вам сделать это за меня, таким образом вы начнете учиться понимать чужой исходный код. Удачи вам в ваших начинаниях.
Помните, ваше усердие будет вознаграждено приобретенными знаниями.
До встречи. sea_src.rar - студийный проект с исходным кодом,
seashell_EXE.rar - запускаемый файл игры.
Windmill 2
WindMill 2D Game Engine
|
|
|
| |
| nilrem | Дата: Воскресенье, 04 Октября 2009, 09:32 | Сообщение # 10 |
|
Просветленный разум
Сейчас нет на сайте
| Лекция 4. Сложные типы данных. Копаем глубже.
(или роем себе могилу)
Здравствуйте. В названии урока присутствует слово сложные, и это действительно так. По сравнению с предыдущими, этот урок будет намного сложнее. Поэтому игры сегодня мы делать не будем. По мере изложения нового материала я буду демонстрировать короткие примеры. Каждая мелочь будет продемонстрирована и опробована на практике. Не волнуйтесь, если что-то будет казаться непонятным. Со временем все станет на свои места.
И еще, мне тут в аське сказали, что какие же это к черту уроки, если их нужно полдня читать. Ну, я, в принципе, согласен. Так что с этого момента это не уроки, а лекции, я и раньше употреблял это термин. А лекции сами по себе теперь разбиты на разделы – уроки. Их так и нужно осваивать – прочитали урок, поняли, переходим дальше.
Урок 1. Как информация хранится в компьютере
Прежде чем изучать дальнейший материал, немного поговорим о том, как же все данные хранятся в памяти компьютера. Сравним память компьютера с книгой, в которой информация представлена в виде текста. В свою очередь этот текст состоит из слов, слова из букв. На этом разбиение на простые составляющие заканчивается. Но не для компьютера. Память компьютера состоит из электронных запчастей, которые могут находится всего в двух состояниях. Возьмем за аналогии обычный выключатель(или включатель). Он может быть или включен или выключен. Так и в компьютере один «кусочек» памяти может принимать значение условно считаемое 0 или 1.
Если вы думаете что этого мало, вспомните азбуку Морзе. Там с помощью тех же двух символов без труда передают весь алфавит и цифры. Вот о цифрах мы позже и поговорим.
Кто-то когда-то назвал эти 0 и 1 битом. Потом придумали объединить 8 битов вместе и назвать их байтом. С байтами мы и будем иметь дело. Также есть такие понятия как Килобайт – 1024, мегабайт – 1024 килобайта, гигабайт – 1024 мегабайта, терабайт и т.д. Почему именно 1024, потому что здесь учитывается степень двойки.
Сделаю небольшое отступление, тоже касающееся хранения информации, но не в памяти, а на жестком диске, по-другому винчестере. На этих устройствах хитрые производители часто указывают емкость не в мегабайтах, а в миллионах байт, а это существенная разница.
Вот пример. Есть у меня самсунговский диск емкостью 40 000 миллионов байт, то есть как бы сорок гигабайт. А вот фигушки.
40 000 000 000 / 1024 = 39062500 килобайт
39062500 / 1024 = 38146 мегабайт
38146 / 1024 = 37,25 гигабайт
Вот так нас обманывают.
Ладно, завязываем с отходом от темы. Сейчас я расскажу, как с помощью всего двух символов 0 и 1 в компьютере записывается все что угодно. Слышали ли вы когда-нибудь такой термин – система счисления. Система счисления это такая математическая система, в которой используется определенное количество цифр(количество цифр еще называют основанием). Не путаем понятие цифра и число. Цифра – это знак, символ, а число это математическое значение, состоящее из одной или скольких угодно цифр.
Так вот, в повседневной жизни мы пользуемся десятичной системой счисления, то есть используем десять цифр – от 0 до 9. Число 10 состоит уже из двух цифр и соответственно само цифрой не является.
Вообще, кроме десятичной, система счисления может быть любой, но наибольшей популярностью пользуются - двоичная, десятеричная и шестнадцатеричная.
Двоичная это наши 0 и 1, с десятеричной тоже понятно, но как быть с шестнадцатеричной, если цифр-то всего десять. Все просто, в качестве дополнительных, используются символы латинского алфавита от А до F (в нижнем регистре a и f), то есть 10 это A, а 15 это F.
Надеюсь, это понятно, думаю также не сложно догадаться, что в любой системе исчисления можно записать любое число. Хоть записи и будут выглядеть по-разному, значение их будет идентичным.
ПРИМЕР одно число в трех системах счисления
Десятичная - 100
Шестнадцатеричная - 64
Двоичная – 1100100
Таким образом с помощью наших 0 и 1, то есть с помощью двоичной системы без труда записывается любая информация.
- Но ведь информация бывает не только числовая! – можете возразить вы. Да мы привыкли иметь дело с текстом, но в компьютере каждая буква, или любой другой символ, хранится в виде числа, которое в свою очередь в памяти представлено в двоичном виде. Мы об этом еще поговорим.
Урок 2. Перевод из одной системы счисления в другую
Самый простой способ перевода чисел из одной системы в другую это … стандартный калькулятор операционной системы Windows в его инженерной ипостаси.
Но нам как программистам необходимо, хотя бы теоретически, знать, как это делается вручную. Все системы счисления я затрагивать не буду, а остановлюсь только на привычной нам десятичной и родной для компьютера – двоичной.
Немного теории.
Чтобы перевести число из одной системы счисления в другую нужно представить его в таком виде:
Здесь:
an … a0 – цифры от первой до последней
n – количество цифр, нумерация идет по уменьшению
С – система счисления(например 2, 10, 16 и др.) в соответствующей позиции n–ной степени.
Из вышеприведенной формулы следует(хотя вряд ли, подозреваю что вы в нее не въехали, но ничего, дальше поймете), что для перевода из большей системы в меньшую необходимо провести целочисленное деление числа на основание(систему счисления). Остаток это и будет наша цифра a0. Затем предыдущий результат от деления вновь делим нацело и получаем a1. И так далее пока результат от деления не будет равен 0.
Теперь пример перевода из десятичной в двоичную:
Возьмем число 75.
75 / 2 = 37; остаток 1.
37 / 2 = 18; остаток 1.
18 / 2 = 9; остаток 0.
9 / 2 = 4; остаток 1.
4 / 2 = 2; остаток 0.
2 / 2 = 1; остаток 0.
1 / 2 = 0, остаток 1.
Результат:
Напоминаю, что цифры записываются в обратном порядке.
75 = 1001011
Теперь будем переводить обратно, из меньшей в большую, то есть из двоичной в десятичную. В этом случае нам и понадобится приведенная выше формула.
Проведем обратное преобразование 1001011. Вычисления должны идти по требуемой, в нашем случае десятичной системе счисления.
1 * 26 + 0 * 25 + 0 * 24 + 1 * 23 + 0 * 22 + 1 * 21 + 1 = 64 + 8 + 2 + 1 = 75
Также часто в информатике используется шестнадцатеричная система. С ней компьютер способен работать и так. То есть можно сразу давать ему такие числа, предварительно сообщив об этом. Чтобы программа знала о том, что предлагаемое число в 16ричной системе, используется специальная запись с префиксом 0х.
0х10, 0х50, 0х5А, 0х1А9В – это все числа в шестнадцатеричной системе.
Аналогичная ситуация с восьмеричной системой. Здесь префикс – 0, а запись 0144, 0456 означает, что число восьмеричное, при этом запись 08 вызовет ошибку, так как в восьмеричной системе цифры 8 нет.
Кроме этого возможно переключение вывода информации в консоли, что называется на лету. Для этого достаточно сообщить об этом оператору cout, передав ему определенную инструкцию. Для десятичной системы - dec, для шестнадцатеричной – hex и oct для восьмеричной.
Code
cout << hex; // шестнадцатеричная
cout << 100 << '\n'; // 64
cout << 0x64 << '\n'; // 64
cout << 0144 << '\n'; // 64
cout << oct; // восьмеричная
cout << 100 << '\n'; // 144
cout << 0x64 << '\n'; // 144
cout << 0144 << '\n'; // 144
cout << dec; // возврат к десятичной
cout << 100 <<'\n'; // 100
cout << 0x64 <<'\n'; // 100
cout << 0144 <<'\n'; // 100
На этот с системами счисления заканчиваем. Примеры кода с преобразованием будут позже.
Windmill 2
WindMill 2D Game Engine
|
|
|
| |
| nilrem | Дата: Воскресенье, 15 Ноября 2009, 16:58 | Сообщение # 11 |
|
Просветленный разум
Сейчас нет на сайте
| Урок 3. Размер данных и диапазон значений. Модификаторы типа. Как мы уже знаем байт состоит из восьми битов. Поскольку количество этих самых битов небольшое, то и, естественно, что записать с их помощью много чисел не получится. Поэтому размер переменных увеличивают до нескольких байтов. При этом занимаемое ими в памяти место увеличивается.
Теперь нам необходимо возвратится к уже изученным типам данных и узнать о них то, о чем я раньше умолчал. Сейчас я расскажу, сколько каждый тип данных занимает места в памяти и в каком диапазоне он может принимать значение.
Но прежде чем это делать, нужно объяснить еще один момент. Из школьных уроков математики вы должны знать, что существую положительные и отрицательные числа. В языке С++ такие числа относятся к знаковым, то есть предполагается что перед числом стоит плюс или минус. Ну и поскольку есть знаковые, то можно предположить что есть и беззнаковые, То есть всегда положительные, почему так, поймете дальше. Такие числа имеют отдельное обозначение - unsigned. Это ключевое слово ставится при объявлении переменной перед типом. Знаковые переменные тоже имеют обозначение - signed, но поскольку переменная по умолчанию считается знаковой, то его можно не использовать.
Пример:
а запись: идентична: ПРЕДУПРЕЖДЕНИЕ!!!
Применение unsigned к float или double превращает тип переменной в int. Ключевые слова signed и unsigned называются модификаторы(или спецификаторы) типа. Кроме названных есть еще несколько спецификаторов. Например, ключевые слова short и long которые применяются по отношению к целочисленному типу и увеличивают или уменьшают диапазон значений ну и размер.
Теперь я приведу небольшую таблицу в которой представлены типы даны, занимаемый ими размер и диапазон значений. Стоп. Лучше мы напишем для этого программу. Чтобы это сделать, нам необходимо узнать, как получить размер переменной определенного типа и как вычислить диапазон.
С размером все просто. В языке С++ есть специальная функция, которая умеет это делать – sizeof(). Ну а диапазон нам придется определять вручную, с помощью цикла. Помните, как мы это делали для генератора случайных чисел. Здесь будет нечто подобное, но мы воспользуемся интересным свойством переменных. Допустим, переменная имеет диапазон от 0 до 255. И сейчас ей присвоено максимальное значение 255. Как вы думаете, что будет, если прибавить к нему единицу? Значение переменной изменится на 0. Переменная будто закольцована сама на себя, и за пределы допустимого значения никогда не выйдет. Так и будет изменяться по кругу, в ту или иную сторону. Закольцованность работает в обе стороны, то есть если переменная равна нолю и отнять единицу, то значение станет 255.
В общем вот код: Code #include <iostream>
using namespace std;
void main ()
{
setlocale(0,"");
bool b;
char c;
int i=0;
short int si=0;
long int li=0;
unsigned int ui=0;
unsigned short int usi=0;
unsigned long int uli=0;
float f=0;
long float lf=0;
double d=0;
long double ld=0;
cout<<"\tТип данных\t\t"<<"Размер\t"<<"Диапазон значений\n\n";
cout<<"\t"<<"bool"<<"\t\t\t"<<sizeof(b)<<"\n";
cout<<"\t"<<"char"<<"\t\t\t"<<sizeof(c)<<"\n";
int min=0;
int max=0;
do
{
++i;
if(i>max)
max=i;
else
{
if(i<min)
min=i;
}
}
while(i!=0);
cout<<"\t"<<"int"<<"\t\t\t"<<sizeof(i)<<"\t"<<min<<" ... "<<max<<"\n";
min=0;
max=0;
do
{
++si;
if(si>max)
max=si;
else
{
if(si<min)
min=si;
}
}
while(si!=0);
cout<<"\t"<<"short int"<<"\t\t"<<sizeof(si)<<"\t"<<min<<" ... "<<max<<"\n";
long int lmin=0;
long int lmax=0;
do
{
++li;
if(li>lmax)
lmax=li;
else
{
if(li<lmin)
lmin=li;
}
}
while(li!=0);
cout<<"\t"<<"long int"<<"\t\t"<<sizeof(li)<<"\t"<<lmin<<" ... "<<lmax<<"\n";
unsigned int uimin=0;
unsigned int uimax=0;
do
{
++ui;
if(ui>uimax)
uimax=ui;
else
{
if(ui<uimin)
uimin=ui;
}
}
while(ui!=0);
cout<<"\t"<<"unsigned int"<<"\t\t"<<sizeof(ui)<<"\t"<<uimin<<" ... "<<uimax<<"\n";
unsigned short int usimin=0;
unsigned short int usimax=0;
do
{
++usi;
if(usi>usimax)
usimax=usi;
else
{
if(usi<usimin)
usimin=usi;
}
}
while(usi!=0);
cout<<"\t"<<"unsigned short int"<<"\t"<<sizeof(usi)<<"\t"<<usimin<<" ... "<<usimax<<"\n";
unsigned long int ulimin=0;
unsigned long int ulimax=0;
do
{
++uli;
if(uli>ulimax)
ulimax=uli;
else
{
if(uli<ulimin)
ulimin=uli;
}
}
while(uli!=0);
cout<<"\t"<<"unsigned long int"<<"\t"<<sizeof(uli)<<"\t"<<ulimin<<" ... "<<ulimax<<"\n";
cout<<"\t"<<"float"<<"\t\t\t"<<sizeof(f)<<"\n";
cout<<"\t"<<"long float"<<"\t\t"<<sizeof(lf)<<"\n";
cout<<"\t"<<"double"<<"\t\t\t"<<sizeof(d)<<"\n";
cout<<"\t"<<"long double"<<"\t\t"<<sizeof(ld)<<"\n";
cin.get();
}
Главную работу здесь выполняет вот этот кусочек, который повторяется несколько раз с некоторыми изменениями, в основном касающимися типа данных: Code
int min=0;
int max=0;
do
{
++i;
if(i>max)
max=i;
else
{
if(i<min)
min=i;
}
}
while(i!=0);
cout<<"\t"<<"int"<<"\t\t\t"<<sizeof(i)<<"\t"<<min<<" ... "<<max<<"\n";
Работает он как и в пример с генератором случайных чисел. Цикл начинается с нуля и завершается когда будет пройден круг и переменная вновь станет равна нолю. Тип переменных, в которых хранится минимальное и максимальное значение, должно соответствовать проверяемому типу, иначе оно может туда не поместится.
Ну а в последней строке происходит отображение результата, в ней же с помощью sizeof вычисляется размер переменной в байтах. Вот такая табличка получится в результате работы нашей программы: 
Считать диапазон float и других последующих типов я не стал. Программа и так работает несколько минут, а тронь я float, работала бы несколько дней.
Дело в том, что при одинаковом размере с типом int, float имеет диапазон от -1.0Е+37 до 1.0Е+37.(Если кто не знает что это значит, объясняю. +37 означает что нужно передвинуть точку вправо (от единицы) на тридцать сем знаков, подставив ноли. В результате получится число в котором 38 цифр. (Как его назвать я даже не знаю. Знаю есть квинтиллион, вроде 18 нолей, так ведь и это очень мало) Куда тут int с его 4 миллиардами.
Ладно. Как видно из получившейся у нас таблицы, некоторые типы данных при одинаковом размере отличаются диапазоном значений. В первую очередь это касается знаковых и беззнаковых. Сейчас я объясню, почему так происходит. Если число имеет определенный знак, не важно, плюс это или минус, то естественно, что этот знак должен где-то храниться. В переменной под знак резервируется крайний левый бит, также называемый старшим битом. Если он равен 0 то переменная положительная(знак + ), если 1 то отрицательная(знак -). Потеря всего одного бита уменьшает значение переменной в два раза. Она как бы делится пополам - одна половина для положительных, другая - для отрицательных чисел, что вы и можете видеть.
Упомянув о спецификаторах типа не возможно не рассказать еще об одном – const. Объявленную с его помощью переменную невозможно изменить. Такую переменную называют константой, и используют для хранения определенных постоянных значений. При объявлении константы ей нужно сразу же присваивать значение.
Пример:
Если где-то далее в коде вы попытаетесь ее изменить, компилятор сразу же сообщит об ошибке. Если вы не присвоите константе значения сразу, а попытаетесь сделать это позже, опять же получите ошибку.
Так делать нельзя:
Code
const int p;
p = 3,14; // ошибка. Изменить константу нельзя. Урок 4. Массивы
Сегодняшняя лекция полностью посвящена данным, поэтому сейчас я расскажу еще об одном их типе. Хотя чисто технически это не самостоятельный тип, а способ представления уже известных. Очень часто программы содержат множество, тысячи и миллионы, переменных. Чтобы хоть как-то облегчить жизнь программистам некоторые близкие по смыслу переменные можно объединять в последовательности. Такую последовательность называют массивом. Одномерный массив Одномерный массив это список, последовательность близких по смыслу переменных. Как и любые другие типы данных, массив также нужно объявлять. Синтаксис объявления такой: Тип_данных имя_массива[размер массива]; Здесь:
Тип данных может быть любым известным вам типом. Ограничений нет.
Имя массива также может быть любым, главное чтобы оно соответствовало описанным ранее требованиям к именам.
Размер массива – здесь внутри квадратных скобок указывается, сколько именно переменных будет содержаться в массиве. Каждая такая переменная называется элементом массива. Теперь, зная синтаксис, объявим массив, состоящий из 10 элементов типа int: Доступ к конкретному элементу массива выполняется с помощью его индекса – порядкового номера. Для этого просто указываем индекс в квадратных скобках: Здесь мы обратились к элементу с индексом пять. Но не к пятому по порядку. Важно запомнить что отсчет в языке программах на языке С++ начинается с 0.
То есть самый первый элемент имеет индекс 0, второй – 1. И так далее. Так что в нашем массиве с 10 переменными, индекс последней переменной будет 9. 
Инициализация массива
Свежесозданный массив является пустым. Значение, которое содержат его элементы непредсказуемо и может быть каким угодно в диапазоне объявленного типа данных.
Поскольку пустые массивы, с содержащими мусор элементами, никому не нужны, их нужно как то заполнить. Этот процесс называется инициализацией массива. Инициализировать массив можно несколькими способами.
Например, можно просто присваивать значение каждому элементу. Code
ar[0] = 10;
ar[3] = 17; Если всем элементам массива нужно присвоить определенное значении или последовательность значений, то это удобно делать в цикле.
Вот пример кода: Code #include <iostream>
using namespace std;
void main()
{
setlocale(0,""); // подобная запись устанавливает в консоли язык, используемый в системе по умолчанию.
int ar[10]; // обьявляем масив
for(int i=0;i<10;i++)
{
ar[i]=0; // присваиваем значение элементам
}
for(int i=0;i<10;i++) // цикл, воторый выводит значение елементов
{
cout<<"Элемент ar["<<i<<"] = "<<ar[i]<<'\n';
}
cin.get();
}
Как он работает, видно из комментариев. Есть еще один способ инициализации массива. Он используется во время его объявления. Вот синтаксис: Тип_данных имя_массива[размер массива] = {список_значений}; Code
#include <iostream>
using namespace std;
void main()
{
setlocale(0,"");
int ar[10]={1,2,3,4,5,6,7,8,9,10}; // обьявляем и инициализируем массив
for(int i=0;i<10;i++)
{
cout<<"Элемент ar["<<i<<"] = "<<ar[i]<<'\n';
}
cin.get();
} Количество значений в строке {1,2,3,4,5,6,7,8,9,10} желательно, но не обязательно должна соответствовать размеру массива. Кстати, в целях экономии места подобным способом можно объявить массив, не указывая его размер. Code Тип_данных имя_массива[ ] = {список_значений}; В таком случае размер массива будет равен количеству значений. То есть в результате объявления: будет создан массив, содержащий три элемента. Таким способом часто пользуются при объявлении массивов символов, или по-другому строк. Code [b]Массив символов[/b]
Строка это одномерный массив, каждый элемент которого относится к типу данных char, а последний символ нулевой (‘\0’) .  image004.png image004.png
Объявлять символьный массив можно как любой другой массив, например, так: Code char str[7]={'q','w','e','r','t','y','\0'}; Чтобы не заморачиваться с нулевым символом и размером лучше всего использовать следующий способ: здесь размер задается сам, а благодаря использованию кавычек нулевой символ подставляется автоматически. Кстати этот самый нулевой символ используется для того, чтобы программа знала где строка заканчивается.
То есть чтобы при печатании строки Code cout << "чтобы программа знала, что остановится нужно после слова здесь"; Я проиллюстрирую это примером: Code #include <iostream>
using namespace std;
void main()
{
setlocale(0,"");
char str[]="qwerty"; // обьявляем и инициализируем массив
int i=0;
while(str[i]!='\0') // пока это не нулевой символ
{
cout<<str[i++]<<'\n';
}
cin.get();
}
Здесь в цикле печатаются символы, до тех пор, пока не будет достигнут нулевой символ. Приблизительно так и работает cout. Раньше мы вводили к компьютер только числа, сейчас же настало время научиться вводить текст. Делается это с помощью все того же оператора cin.
Просто необходимо создать соответствующую переменную, то есть массив символов, и передать ей ввод. Code #include <iostream>
using namespace std;
void main()
{
setlocale(0,"");
char str[50]; // обьявляем массив
cin>>str; // считываем строку
cout<<"вы ввели: "<<str; //отображение
cin.get();
cin.get();
}
Заметьте, при передаче ввода указывается только имя массива без использования квадратных скобок. То же самое и при выводе с помощью cout. И еще количество введенных символов не должно превышать заявленный размер массива.
Сейчас поясню, почему. Элементы массива размещаются в памяти компьютера друг за другом в смежных ячейках, то есть так, как это показано выше на рисунке. Если количество символов окажется больше, чем размер массива, программа без зазрения совести запишет их последующие ячейки. При это данные, которые были записаны в них ранее будут безвозвратно утеряны. В результате произойдет сбой в работе программы.
Так что будьте внимательны. Создавая массив, заранее просчитывайте, сколько места понадобится.
Описанная здесь проблема касается не только строк, это проблема любых массивов вообще. 
Многомерный массив Помимо простых одномерных массивов существуют и многомерный. Если одномерный можно сравнить с несколькими коробками, содержащими определенные предметы-значения, то многомерный массив это коробки в которых содержатся другие коробки. И так далее.
Объявляются они следующим образом: Code Тип_данных имя_массива[размер_1] [размер_2]… [размер_N]; Пример: Code
float map[10][10]
int terra[5][50][300];
char text[100][2][5][500][3][15654][45][10][15];
Мерность массива может быть сколько угодной, но чаще всего используются двухмерные. Их я и буду использовать для примера.
Зачем же могут понадобится многомерные массивы. Примеров на самом деле можно придумать сколько угодно, но я остановлюсь на том, что ближе всего к разработке игр. Допустим, есть следующий массив: Вот как его можно представить графически: 
На что похоже. Ну, например, на урезанное шахматное поле. Таким способом, сделав массив 8 на 8 элементов можно представить шахматную доску, или если брать шире, то вообще любое игровое поле. А содержащееся значение могут, например, означать силу или количество находящихся там существ, или просто тип юнита.
Инициализируют многомерные массивы также как и обычные. Разве что есть небольшое отличие в записи. Code int map[5][5]= {{1,2,3,4,5},
{2,50,43,75,10},
{3,44,45,1,9},
{4,16,8,5,1},
{5,5,8,8,7}};
Здесь числа собраны в группы по количеству элементов.
Теперь, чтобы лучше понять, что представляют из себя многомерные массивы, напишем небольшую программу. Поскольку урок серьезный, напишем мы таблицу умножения)
Вот код. Он небольшой, так что разобраться сможете: Code #include <iostream>
using namespace std;
void main()
{
setlocale(0,"");
int tab[10][10]; //обьявляем массив
tab[0][0]=0;
for(int i=1;i<10;i++)
{
tab[i][0]=i; // заполняем верхнюю строку
tab[0][i]=i; // заполняем левый крайний столбик
}
for(int y=1;y<10;y++)
{
for(int x=1;x<10;x++)
{
tab[x][y]=x*y; // заполняем всю таблицу
}
}
for(int y=0;y<10;y++)
{
for(int x=0;x<10;x++)
{
cout<<tab[x][y]<<'\t'; // печатаем таблицу
}
cout<<"\n\n";
}
cin.get();
}
Укажу лишь на вложенные цикл: Code for(int y=1;y<10;y++)
{
for(int x=1;x<10;x++)
{
tab[x][y]=x*y; // заполняем всю таблицу
}
} Именно так здесь заполняются «коробки, вложенные в коробки».
Завершая с массивами, выполняю данное ранее обещание и привожу код преобразования из десятичной системы в двоичную: Code #include <iostream>
using namespace std;
void main()
{
setlocale(0,"");
cout<<"введите число от 0 до 255 ";
int i;
cin>>i;
int c[8]; //массив в котором будут хранится биты (1 или 0)
int ic=7;
for(int x=0;x<8;x++)
{
c[x]=0; // обнуляем элементы массива
}
while(i!=0) // пока результат деления не равен 0
{
c[ic--]=i%2; //присваиваем элементу массива остаток, являющийся битом
i=i/2; // делим на 2
}
for(int x=0;x<8;x++)
{
cout<< c[x]; //отображаем результат
}
cin.get();
cin.get();
}
Здесь массив используется для хранения значений битов. Если бы нам не требовалось отобразить их в обратном порядке до полученного при делении, то мы бы могли обойтись без массива.
Также обращаю ваше внимание на строку: здесь используется инкремента в постфиксной записи, поэтому сначала вычисляется все выражение и только после переменная ic уменьшается на единицу. Для преобразования типов существует намного более простой код. Его я приведу, когда мы научимся работать персонально с каждым битом.
Windmill 2
WindMill 2D Game Engine
|
|
|
| |
| nilrem | Дата: Воскресенье, 15 Ноября 2009, 17:12 | Сообщение # 12 |
|
Просветленный разум
Сейчас нет на сайте
| Урок 5. Манипуляция с битами Думаю, раз биты такие важные, что с них мы начали наш урок, нужно познакомится с ними еще ближе. В языке С++ есть несколько операторов, с помощью которых можно проводить различные действия над битами: ~ Битовое Не. Меняет значение бита на противоположное. Вообще, если сравнить 1 с логическим true, а ноль с логическим false (как оно в общем-то и есть) здесь можно использовать аналогию с логическими операторами. Помните пример: Code !true возвратит false
!false возвратит true Ну а вот битовый аналог: Code ~1 (true) возвратит 0 (false)
~0 (false) возвратит 1 (true) & Битовое И. Как и логический вариант, этот оператор возвращает 1 если оба аргумента равны единице, во всех остальных случаях 0. Code 1 (true) & 1 (true) возвратит 1 (true)
1 (true) & 0 (false) возвратит 0 (false)
0 (false) & 0 (false) возвратит 0 (false) Битовый & поочередно применяется ко всем битам числа. Вот как это работает: 11010 & 10101 равно 10000 Немного отформатируем, чтоб было понятнее:
11010 &
10101 равно
10000 Если перевести все в привычную нам десятичную систему, то будет так: 26 & 21 = 16 Вот такая вот арифметика)
Воплотим ее в код: Code #include <iostream>
using namespace std;
void main()
{
cout<< (26 & 21);
cin.get();
}
| Битовое ИЛИ. И опять знакомая ситуация. Если один из аргументов равен 1, то 1 и будет возвращено . Code 1 (true) | 1 (true) возвратит 1 (true)
1 (true) | 0 (false) возвратит 1 (true)
0 (false) | 0 (false) возвратит 0 (false) Пример:
11010 |
10101 равно
11111
26 | 21 = 31 Измените предыдущий пример и убедитесь, что я прав. ^ Исключающее ИЛИ. А вот это нечто новое. Такого мы еще не видели. Оператор ИЛИ возвращает единицу, только если один(только один) из аргументов равен 1. Code 1 (true) ^ 1 (true) возвратит 0 (false)
1 (true) ^ 0 (false) возвратит 1 (true)
0 (false) ^ 1 (true) возвратит 1 (true)
0 (false) ^ 0 (false) возвратит 0 (false) Пример:
11010 ^
10101 равно
01111 В привычном нам, десятичном, виде: 26 ^ 21 = 15 Операторы сдвига Помимо логических, для работы с битами также используются операторы сдвига. Это уже знакомые нам << и >>. Они сдвигают все биты числа соответственно влево или вправо, заполняя освободившиеся нолем.
Синтаксис использования этих операторов выглядит так: переменная << число битов
переменная >> число битов здесь число битов, это значение, означающее на сколько нужно произвести сдвиг.
Пример: 01011010 << 1 даст
10110100 а 01011010 >> 1 даст
00101101 Отлично, сдвигает. Нам то что с того.
Ну например использование комбинация битовых операторов позволяет узнавать или изменять значение каждого бита на свое усмотрение. Для этого придется немного напрячь мозг. Чтобы понять приведенные далее коротенькие примеры необходимо знать то, что я излагал выше. Проверка бита
Итак, в первую очередь разберемся, как узнать значение конкретного бита переменной v.
Для этого используется вот такое очень простое выражение: Code (v & (1 <<n))? Бит = 1: Бит = 0; Эта запись, если вы помните прошлые уроки, использует условный оператор и может быть записана следующим образом: Code if(v & (1 << n))
{
Бит = 1;
}
else
{
Бит = 0;
} Где:
v - переменная,
n - номер бита. Работает оно так. Сначала с помощью оператора сдвига создается переменная, в которой интересующий нас бит равен 1. Для этого переменная 1 имеющая двоичное представление 00000001, сдвигается на нужное количество битов влево. Допустим нам нужно узнать значение второго бита. Вспомним, что биты нумеруются от ноля. (1 << 2)
00000001 << 2
Результат сдвига
00000100 Далее применяем битовый И. Если у переменной второй бит 1 то в результате выражения: Code 11111111
& 00000100
Получим
00000100 то есть (true) Если же второй бит равен нолю то: Code 11111011
& 00000100
Получим
00000000 то есть (false) Ну а дальше в действие вступает условный оператор, который определяет правдивое выражение или ложное и присваивает соответствующую цифру.
Далее я продемонстрирую как с помощью описанного выше способа выполнить преобразование из десятичной системы счисления в двоичную. Code #include <iostream>
using namespace std;
void main()
{
setlocale(0,"");
cout<<"введите число от 0 до 255 ";
int i;
cin>>i;
for(int n=7;n>=0;n--)
{
cout<<(i & (1 << n) ? 1 : 0);
}
cin.get();
cin.get();
}
Намного проще, не правда ли. Если кому-то непонятно, замените строку: Code cout<<(i & (1 << n) ? 1 : 0); на: Code if(i & (1 << n))
{
cout<<1;
}
else
{
cout<<0;
} Теперь дошло? Установка бита в 1
Проверять биты мы научились. Менять их значение еще проще. Здесь даже условный оператор не нужен. Установка бита в 1 выполняется с помощью такого выражения: Здесь, как и в прошлом случае используется сдвиг для получения переменной, в которой значение конкретного бита 1, остальных 0.
Далее используется битовый оператор ИЛИ. Если у переменной второй бит и так 1 то в результате выражения: 11111111 | 00000100 Получим 11111111 Если же второй бит равен нолю то: 000000000 | 00000100 Получим 00000100 Далее результат присваивается исходной переменной. Пример кода: Code #include <iostream>
using namespace std;
void main()
{
setlocale(0,"");
int i=0;
cout<<"i = "<<i<<" = ";
for(int n=7;n>=0;n--)
{
cout<<(i & (1 << n) ? 1 : 0);
}
i |= (1 << 0); // устанавливаем нулевой бит в 1
cout<<"\nустанавливаем нулевой бит в 1\n";
cout<<"i = "<<i<<" = ";
for(int n=7;n>=0;n--)
{
cout<<(i & (1 << n) ? 1 : 0);
}
i |= (1 << 7); // устанавливаем 7 бит в 1
cout<<"\nустанавливаем 7 бит в 1\n";
cout<<"i = "<<i<<" = ";
for(int n=7;n>=0;n--)
{
cout<<(i & (1 << n) ? 1 : 0);
}
cin.get();
cin.get();
} Здесь, вместо строки у меня записано Для сокращения записи я воспользовался составным присваиванием |=. Установка бита в 0
А теперь обнулим бит с помощью: (Здесь тоже составное присваивание &=) И вновь используется сдвиг, для получения переменной, в которой значение конкретного бита 1, остальных 0. Далее с помощью битового НЕ значение всех битов меняется на противоположное. ~00000100 дает 11111011 Затем, как и в случае проверки, используется битовый И.
Если у переменной второй бит 1 то в результате выражения: 01010101 & 11111011 Получим 01010001 Если же второй бит уже равен нолю, то там и менять нечего: 10101010 & 11111011 Получим 10101010 Этот код нужно добавить в приведенный выше пример перед cin.get();. Code i &= ~(1 << 0); // обнуляем нулевой бит
cout<<"\nобнуляем нулевой бит\n";
cout<<"i = "<<i<<" = ";
for(int n=7;n>=0;n--)
{
cout<<(i & (1 << n) ? 1 : 0);
}
i &= ~(1 << 7); // обнуляем 7 бит
cout<<"\nобнуляем 7 бит\n";
cout<<"i = "<<i<<" = ";
for(int n=7;n>=0;n--)
{
cout<<(i & (1 << n) ? 1 : 0);
} Вот мы и научились управлять данными на таком тонком уровне как биты. Для полного счастья нам не хватает только добраться до памяти, а конкретно до тех ячеек, в которых вместе со своими битами хранятся переменные. Чем-то подобным мы далее и займемся. Урок 6. Указатели На этой лекции я решил подвести черту под типами данных. Поэтому настала очередь рассказать еще об одном – об указателях. Этот тип данных является чем то вроде камня преткновения в языке программирования С++. Благодаря указателям программы приобретают необычайную гибкость и непревзойденную скорость, но благодаря им же появляются многочисленные серьезные, трудно ловимые баги и ошибки.
Итак, указатель это переменная, хранящая в себе адрес другой переменной. Чтобы понять, что я имею ввиду нужно знать, что значит адрес переменной. Адрес
Как вы уже знаете, память компьютера состоит из битов, которые в свою очередь собраны в байты. У каждого байта имеется свой адрес, представленный в виде шестнадцатеричного числа.
Каждая переменная занимает в памяти от одного до нескольких байтов. Так вот, адресом переменной становится адрес ее первого байта. Чтобы получить адрес переменной используется оператор взятия адреса - &.
Этот оператор нам уже попадался под видом битового И. Теперь же с его помощью мы будем получать адрес. Действие, которое этот оператор выполняет, зависит от способа его записи. Если он стоит между двумя переменными то это И, если он стоит перед одной переменной то это оператор взятия адреса. Операторы которые применяются всего к одной переменной называются унарными. Использование указателей.
Как получить адрес, мы уже знаем. Теперь познакомимся с синтаксисом объявления указателя. Code тип_данных *имя_переменной Здесь ключевую роль играет унарный оператор звездочка *. С помощью которого переменная и становится указателем. Как и при объявлении других переменных, здесь также есть тип данных. Здесь указывается тип данных переменной, на которую ссылается указатель.
Пример Code int i=1564;
int *pi; // обьявление указателя
pi = & i; // взятие адреса пример можно сократить Code int i=1564;
int *pi= & i; // обьявление указателя и взятие адреса Здесь в имени указатели, согласно венгерской нотации, используется префикс p. Чтобы не запутаться в своей программе и знать что переменная это указатель, советую вам использовать его всегда.
Теперь напишем небольшую программу, которая выдаст нам адреса нескольких переменных. Code #include <iostream>
using namespace std;
void main()
{
setlocale(0,"");
int s=50;
int i=456;
double d=4.1456;
int *ps = &s;
int *pi = &i;
double *pd = &d;
cout<<"адрес переменной s "<<ps<<'\n';
cout<<"адрес переменной i "<<pi<<'\n';
cout<<"адрес переменной d "<<pd<<'\n';
cin.get();
cin.get();
}
Хорошо, объявлять и присваивать адрес указателю мы научились. Но как получить значение, хранящееся по определенному адресу. Для этих целей используется оператор разыменования указателя, и это все та же звездочка *. Если в предыдущем примере в строках отображения адреса добавить звездочки, программа вместо адреса напечатает значения. Добавьте этот код в предыдущий пример: Code cout<<"\nзначение переменной по указателю ps "<<*ps<<'\n';
cout<<"значение переменной по указателю pi "<<*pi<<'\n';
cout<<"значение переменной по указателю pd "<<*pd<<'\n';
Все просто.
С помощью разыменования указателя можно не только получить, но и изменить значение переменной. Делается это так: Code int i=456;
int *pi = &i;
*pi = 30; Понять запись можно так. Вначале с помощью звездочки мы обращаемся к значению и присваиваем ей новое. Пример кода будет дальше.
Теперь я приведу пример неосторожного использования указателей. Вот что случится, если случайно, посредством указателей, присвоить переменной с типом int значение с типом double: Code #include <iostream>
using namespace std;
void main()
{
setlocale(0,"");
int s=50;
int i=456;
int a=785;
cout<<"s "<<s<<'\n';
cout<<"i "<<i<<'\n';
cout<<"a "<<a<<'\n';
double *pd = (double*)&i;
*pd = 13.4568;
cout<<"s "<<s<<'\n';
cout<<"i "<<i<<'\n';
cout<<"a "<<a<<'\n';
cin.get();
cin.get();
}
Здесь
Присваивание значения через указатель.
В этой программе есть непонятная нам строка. Code double *pd = (double*)&i; а конкретно (double*)&i. Подобная запись называется явным преобразованием типов. Указав при присваивании перед переменной в скобках новый тип, мы получим значение указанного типа.
Пример: Code int i = (int)3.14; // преобразовываем float в int
int i = (int)'a'; // char в int
char c = (char)100; // и наоборот
В некоторых случаях программа может делать преобразования самостоятельно (неявное преобразование). А иногда, как и в примере с указателями, это нужно делать вручную, иначе компилятор выдает ошибку.
Но вернемся к нашему примеру, что же будет в результате присваивания int значения double.
Первое - значение переменной будет некорректным. Второе – при работе программы возникнет ошибка, связанная с порчей памяти, как и в примере с массивами. Что ж, думаю на этом со знакомством с указателями можно завязывать. Но мы к ним еще не раз вернемся. Позже мы узнаем, зачем же они нужны и сможем раскрыть всю их мощь. Послесловие Ну и как обычно пару слов на конец.
Лекция была сложной, и содержала много новой информации. Поэтому вам еще не раз придется к ней возвращаться. Большая часть сведений вам пока не понадобится, разве что для общего понимания. Преобразования систем счисления, манипуляция с битам нужна только в особых случаях. А вот знания про массивы и указатели будут нужны постоянно.
Я надеюсь, что вы прочитали и поняли все, но если что-то пропустили или не совсем поняли, ничего страшного. Можно прочитать и пройтись по примерах еще раз, при этом особое внимание уделяя как раз массивам и указателям.
Ну и если что, спрашивайте.
На этом все, до встречи. ЗЫ: Я надеюсь, что вас не напугали возникшие сложности, и мы еще встретимся. Ведь так?
Windmill 2
WindMill 2D Game Engine
|
|
|
| |
| nilrem | Дата: Воскресенье, 15 Ноября 2009, 17:23 | Сообщение # 13 |
|
Просветленный разум
Сейчас нет на сайте
| Лекция 5. Знакомьтесь - Функции. Здравствуйте.
На третьей лекции вы познакомились с циклами. То есть со способами многократного повторения одного определенного блока кода. Давайте представим себе такую ситуацию. Допустим нам необходимо повторить этот блок кода несколько раз но не в одном месте, а в различных частях программы. Конечно, можно просто написать его несколько раз, более того можно просто этот код скопировать. Но есть способ эффективнее и проще – использовать функции. Урок 1. Функции Когда программы становятся очень большими в коде реально можно потеряться. Единственный способ избежать подобных неприятностей, это разделить программу на несколько частей, и работать с ними по отдельности. Этими частями и будут функции. Такой способ программирования называют Процедурным программированием.(Процедура и функция это одно и тоже).
Что же такое функция, по-простому это отдельный блок кода, имеющий определенное назначение, то есть выполняющий какую-то задуманную программистом работу.
Вообще-то с функциями мы уже встречались. Вспомните, когда мы работали с генератором случайных чисел, мы получали системное время с помощью функции time(), устанавливали начальное значение генератора с помощью функции srand(), ну а само число получали с помощью rand(). Использование функции можно разделить на три этапа:
1. Объявление функции
2. Определение функции
3. Вызов. Объявление функции
Объявление сообщает компилятору о существовании некой функции. Вот синтаксис: Code
Тип_возвращаемого_значения имя_функции(список агрументов); Здесь:
Тип возвращаемого значения – это тип переменной, которую возвращает функция по завершению своей работы. Как я уже сказал, у каждой функции есть свое назначение, она выполняет определенную работу. Возьмем простой пример – функция умеет суммировать два целых числа. Результат этого сложения и будет возвращен в виде целого числа.
Имя функции – это и есть имя. Ведь к функции как то нужно обращаться. К именам функций применимы те же требования что и к именам переменной. Помните главное - имя должно быть понятным.
Список аргументов(еще называют параметры функции) - это записанные в скобках передаваемые функции значения, попросту говоря это список переменных над которыми эта функция будет совершать определенные действия. Объявляются эти аргументы так же как и обычные переменные, и дальнейшем используются внутри функции. Несколько аргументов отделяются друг от друга запятыми. Количество аргументов не ограничено, но им может и не быть вовсе.
И обращаю ваше внимание, что завершает объявление уже знакомые нам точка с запятой.
Пример объявления функций: Подобную запись еще называют прототипом функции. Здесь у нас объявлена функция которая не возвращает никакого значения( тип void – пустой тип) и не принимающая ни одного аргумента. Судя из названия, функция умеет что-то там печатать. Code
int sum(int a, int b); Это уже немного описанный пример. Функция имеет два аргумента типа int. В результате своей работы она возвращает целочисленное значение (int).
При объявлении в списке аргументов функции имя переменной можно не указывать, то есть достаточно только указать тип данных. Вот так: Здесь имена a и b отсутствуют, но они в прототипе не очень-то и нужны. Функций мы еще наобъявляемся, так что не будем тратить время и двигаемся дальше. Определение функции Итак, функцию мы уже объявили. Компилятор уже знает о ее существовании, но понятия не имеет, как она работает. Весь, принадлежащий функции код это и есть определение, по-другому реализация, функции.
Синтаксис такой: Code
Тип_возвращаемого_значения имя_функции(список аргументов)
{
Блок кода;
}
Здесь мы может видеть уже знакомое нам объявление, но без завершающей точки с запятой. Далее в фигурных скобках идет принадлежащий функции код, то есть определение функции.
По-моему все просто, поэтому перейду сразу к примеру. Ранее мы объявили функцию sum(), сейчас напишем ее определение. Code
int sum(int a, int b)
{
return a + b;
} Аргументы int a, int b используются в функции как обычные переменные.
Как мы уже знаем, функция возвращает определенное значение. Для этих целей в примере мы и видим оператор возврата - return.
Синтаксис оператора следующий: Code return возвращаемое значение; Возвращаемым значением также может быть и любое выражение, как в нашем примере это a + b. Оператор возврата имеет самый низкий приоритет, то есть будет выполнен только после того, как все выражение будет вычислено.
Запомните, тип возвращаемого значения обязательно должен соответствовать типу, указанному в объявлении функции.
В одной функции может содержаться несколько операторов return. Чаще всего в следующей конструкции: Code
if(условие)
{
return значение;
}
else
{
return значение2;
} Здесь возвращенное значение зависит от заданного условия. Вызов функции. Чтобы воспользоваться функцией, необходимо произвести ее вызов в нужном месте программы. Для вызова используется следующий синтаксис: Code
имя_функции (значение1, значение2, …) Здесь количество и тип значений должны соответствовать количеству и типу аргументов, объявленных в прототипе вызываемой функции. То есть, для объявленной ранее функции Code
int sum(int a, int b); вызов будет таким: Даже если функция не имеет аргументов, круглые скобки при ее вызове писать обязательно.
Кроме чисел функции также можно передавать переменные соответствующего типа: Code
int x=10;
sum(x, 156); Использование функций. Ну а теперь напишем небольшую программу, в которой используем все, с чем познакомились ранее.
Code
#include <iostream>
using namespace std;
int sum(int, int); //обьявление(прототип) функции
void main()
{
setlocale(0,"");
int a;
int a2;
int b;
cout<<"Введите первое число ";
cin>>a;
cout<<"Введите второе число ";
cin>>a2;
b = sum(a,a2); // вызов функции
cout<<"Сума двух чисел "<<b;
cin.get();
cin.get();
}
int sum(int a, int b) //определение(реализация) функции
{
return a + b;
} В этом примере мы видим все, о чем говорили ранее. Объявление, определение и вызов.
В строке:
Code
b = sum(a,a2); // вызов функции возвращенный функцией результат присваивается переменной b. Пример неплохо иллюстрирует учебный материал, но созданная нами функция бесполезная. Более того, код примера неэффективный и некорректный, поэтому далее, чтобы получше освоить функции и получить еще крупицу опыта, мы его улучшим.
Говоря об эффективности, я имел в виду, что в примере есть бесполезные строки кода, ненужное объявление переменных и другое. От всего этого можно и даже нужно избавится, сделав нашу программу компактнее и быстрее(чисто теоретически, поскольку кода мало и повышение производительности никто не заметит.)
Теперь о корректности. В программе наличествует ввод данных. Подразумевается, что будет ведено какое-то число. Но что если пользователь случайно введет какое-то левое значение?
В программе произойдет сбой. А это не есть хорошо. Поэтому сейчас нам необходимо сделать соответствующую проверку. Поскольку, в случае ввода неверного значения программа должна запросить его повторно и вводить нам нужно несколько значений, получение и проверка данных от пользователя будет производиться внутри одной функции GetDigit(). Вот ее код:
Code
int GetDigit()
{
bool r=true;
char c[20];
cout<<"Введите число ";
while (r) // основной цикл
{
cin>>c; // ввод
for(int i=0;c[i]!='\0';i++) // цикл анализа
{
if(isdigit(c[i])) // проверка цифра или символ
{
r=false;
}
else
{
r=true;
cout<<"Повторите ввод (число давай) ";
break; // принудительное завершение цикла анализа
}
}
}
int i= atoi(c);
return i; // возврат числа
} Работает она следующим образом. Вначале запрашивается ввод. Далее, внутри основного цикла, введенные данные присваиваются переменной с, являющейся массивом символов. Даже если пользователь введет корректное число, все равно оно будет записано в памяти как набор символов. Это необходимо для того, чтобы:
1. При вводе символа не произошел сбой(при попытке присвоить числу значение, содержащее не цифры а символы.)
2. Чтобы мы могли выполнить анализ.
Далее в еще одном цикле, Code for(int i=0;c[i]!='\0';i++) // цикл анализа
{
if(isdigit(c[i])) // проверка цифра или символ
{
r=false;
}
else
{
r=true;
cout<<"Повторите ввод (число давай) ";
break; // принудительное завершение цикла анализа
}
}
до тех пор, пока не встретится конец строки(нулевой символ '\0' ) производится анализ массива. Выполняется проверка каждого элемента на то, является ли он числом или символом. Делается это с помощью стандартной функции isdigit(), возвращающей true если проверяемый символ – цифра. В этом случае анализ продолжается, и если все символы цифры, условие продолжения основного цикла (переменная r) становится ложным. Если же функция isdigit(), возвращает false, условие продолжения основного цикла вновь становится истинным, выводится предложение повторно ввести число, и цикл анализа принудительно завершается оператором break. Принудительное завершение необходимо потому, что после символа может встретится опять цифра и условие станет ложным, тогда как на самом деле ввод то некорректный. После завершения основного цикла мы должны возвратить значения. Поскольку с это массив символов(строка), а нам нужно число, чтобы выполнить соответствующее преобразование, используется еще одна стандартная функция atoi().
(Прототип int atoi(const char *str); Функция принимает указатель на строку, а возвращает число)
Она умеет превращать последовательность символов в число, при условии что символы – цифры. Иначе будет возвращен 0. Здесь нужно быть осторожным, поскольку можно запутаться, ведь строка тоже может быть «0». (Можете сами добавить соответствующую проверку, я этого делать не буду, а ниже приведу более сложный вариант функции GetDigit().) Code
int i= atoi(c);
return i; // возврат числа
здесь с – имя массива, по совместительству являющееся также и указателем. Эту запись можно сократить, ведь абсолютно незачем использовать лишнюю переменную
Code
return atoi(c); // возврат числа Здесь напрямую возвращается результат работы функции atoi©. То есть, можно сказать, что после выполнения работы функция замещается значением возвращаемого ею типа. Поэтому ее и можно использовать в тексте программы непосредственно как значение:
Code
b = sum(5,10)* sum(5,3); аналогом этой записи будет то есть: Надеюсь это уяснили. Теперь внесем в нашу программу изменения, задействуем созданную нами функцию GetDigit(). Не забудьте добавить ее объявление. Теперь функция main() примет такой вид: Code
void main()
{
setlocale(0,"");
int a, a2;
a=GetDigit(); // ввод первого числа
a2=GetDigit(); // ввод второго числа
cout<<"Сума двух чисел "<< sum(a,a2); // вызов функции
cin.get();
cin.get();
} Здесь переменные a и a2 получают корректное значение, возвращенное нашей функцией. ЗАДАЧКА.
До сих пор я не давал вам домашних заданий. Пора это менять. Итак, небольшая задачка. Измените приведенный выше пример так, чтобы переменная а2 оказалась ненужной. Ну а теперь обещанный мной более продвинутый вариант функции GetDigit().
Code
int GetDigit()
{
int d;
cout<<"Введите число ";
while (true)
{
cin >> d;
if ((cin.peek() == '\n'))
break;
else
{
cout << "Повторите ввод (ожидается число ) " << "\n";
cin.clear();
while (cin.get() != '\n')
{
}
}
}
return d;
} Я не буду вам объяснять как она работает. Вы должны попытаться разобраться в ней сами. В этом вам поможет встроенная в студию справка, или если у вас нелады с английским то Интернет.
Основное внимание в этом примере следует уделить новым функциям:
cin.peek()
cin.clear()
cin.get()
Правда с последней вы уже знакомы, но вот что она делает на самом деле вряд ли знаете. Ах да. Я же на протяжении стольких уроков так и не рассказал, как пользоваться справкой . Виноват. Исправляюсь. Хотя там и рассказывать особо нечего.
Как и во всех других Windows приложениях, справка в студии вызывается нажатием клавиши F1. При этом справка здесь умная. Во вновь открывшемся окне выдается информация об элементе, который в данный момент является активным. Чтобы получить информацию о неизвестной вам стандартной функции языка, достаточно поместить на нее курсор и нажать вышеупомянутую клавишу. 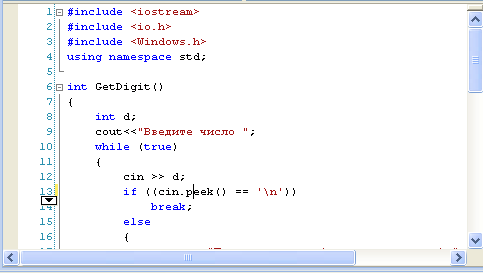 И оп…
Мы получаем всю возможную информацию о данной функции, а также пример ее использования, правда, чаще всего на английском.  Кроме получения информации по функциям в справке содержится еще много чего. Например, можно узнать побольше о какой-нибудь возникшей ошибке. Для этого в списке ошибок выделяем интересующую: 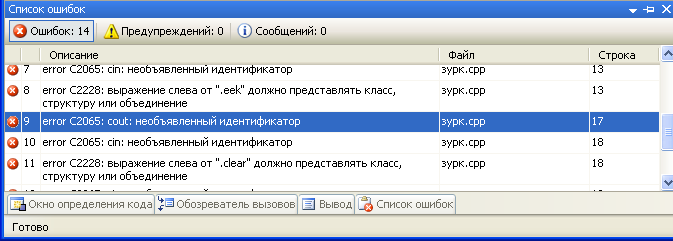 И нажимаем F1. В появившемся окне можно получить информацию не только о природе ошибки, но и подробно, с примерами, узнать причины ее возникновения, а также способы устранения. Кстати если у вас русская студия, то информацию по ошибкам вы получите на родном языке. Эту часть они уже успели перевести. Порадовал я вас немного рисунками, пора возвращаться к основной теме.
Ну вот вы и научились создавать и использовать функции. Теперь сделаю небольшое дополнение. Функции объявлять не обязательно. Вместо объявления функции можно сразу написать ее реализацию. Вот приводимый ранее пример без объявления.
Code
#include <iostream>
using namespace std;
int sum(int a, int b) //определение(реализация) функции вместо ее обьявления.
{
return a + b;
}
void main()
{
setlocale(0,"");
. . .
cin.get();
cin.get();
} Возникает вопрос, зачем же тогда оно нужно. Это вы сможете понять со следующего урока.
Windmill 2
WindMill 2D Game Engine
|
|
|
| |
| nilrem | Дата: Суббота, 23 Января 2010, 16:32 | Сообщение # 14 |
|
Просветленный разум
Сейчас нет на сайте
| Урок 2. Область видимости имен Тема, которую мы рассмотрим на этом уроке, касается не только функций, но и переменных. Поэтому для упрощения буду дальше говорить в основном о них.
Область видимости, это часть программы в которой можно использовать указанную переменную. Бывает она всего двух видов: глобальная и локальная.
Глобальная область это весь наш файл с исходным кодом. Локальная же область, это область, принадлежащая определенному блоку кода, например функции. Локальные области могут быть вложенными друг в друга. Вне своей области локальная переменная невидима, то есть ее нельзя использовать, тогда как глобальная переменная может использоваться в любой объявленной в ней локальной. Локальная область видимости ограничивается фигурными скобками.
Давайте рассмотрим простой пример.
Code
int i;
void main()
{
i=20;
}
void func()
{
i = 321;
}
Это весь код, никаких инклюдов, ничего. Переменная i, объявленная вне главной функции main(), является глобальной. Она видима и внутри main и внутри вообще любой другой функции, например func.
Запомните, глобальная область предназначена только для объявлений или определений. Никакие другие действия в ней не работают. Если вы захотите выполнить, например, присваивание: Code
int i;
i=123; // ошибка
void main()
{
i=20;
}
то компилятор укажет на ошибку. Он решит, что вы пытаетесь заново объявить переменную i, да еще и неправильно, забыв указать тип. Если нужно задать глобальной переменной начальное значение, то делается это сразу при объявлении вот так:
Code
int i=123; // все ОК
void main()
{
i=20;
}
Теперь слегка изменим пример:
Code
void func();
void main()
{
int s;
s = 10; // все ОК
}
void func()
{
s = 321; // ошибка
}
Здесь внутри функции main объявлена переменная с, внутри самой функции с ней можно делать все что угодно. Но попытка использовать ее в функции func вызовет ошибку, поскольку func не принадлежит к области видимости функции main.
Казалось бы, чисто теоретически, можно было бы сделать вот так.
Code
void func();
void main()
{
int s;
s = 10; // все ОК
void func()
{
s = 321;
}
}
Но, не судьба. Запомните, объявлять и писать реализацию функции можно только в глобальной области. Поэтому попытка проделать такое вызовет ошибку.
Следующий пример:
Code
int s;
void main()
{
s = 10; // все ОК
while()
{
s = 321; // тоже все ОК
int w;
w = 128; // все ОК
}
w = 512; // А вот здесь ошибка!
}
Что и где доступно, видно из комментариев. Здесь у цикла есть собственная область видимости. Создать такую область можно, просто выделив что-то фигурными скобками.
Code
int s;
void main()
{
s = 10; // все ОК
{
s = 321; // тоже все ОК
int w;
w = 128; // все ОК
}
w = 512; // А вот здесь ошибка!
}
Здесь тот же пример но без цикла, тем не менее области видимости сохранились. Ключевое значение имеют только фигурные скобки. Но поскольку по синтаксису наличие таких скобок в цикле обязательно, то можно смело говорить что циклы имеют собственную локальную область видимости. Ранее, описывая требования для имен переменных, я говорил, что имя должно быть уникальным. Теперь я хочу это правило дополнить. Имя должно быть уникальным в пределах одной области видимости. То есть:
Code
void func();
void main()
{
int s;
}
void func()
{
int s;
}
Не вызовет никаких проблем. Переменная s является для каждой из функций локальной, посему в другой области она невидима и такая запись не приводит к возникновению ошибки.
Хорошо, теперь вот такой пример:
Code
int s;
void func();
void main()
{
int s;
s = 10;
}
void func()
{
s = 50;
}
Здесь переменная s объявлена также и в глобальной области. Казалось бы, она должна быть видимой и внутри других функций и подобная запись должна приводить к ошибке. Но нет!
Ранее озвученное правило продолжает действовать. Просто если имя объявлено в глобальной области, то везде используется оно, но если в локальной области объявлена переменная с аналогичным именем, то используется локальная.
Поэтому в приведенном выше примере Присваивание s = 10; никак не затрагивает s глобальную. Тогда как в функции func присваивание производится как раз глобальной переменной. Так что можно даже сказать, что это две разные переменные. И следующая программа это продемонстрирует:
Code
#include <iostream>
using namespace std;
int s;
void func();
void main()
{
setlocale(0,"");
int s=30;
cout<<"Локальная s ="<<s;
func();
cin.get();
}
void func()
{
s = 10;
cout<<"\nГлобальная s ="<<s;
}
Результат ее работы наглядно иллюстрирует, что изменение локальной переменной никак не влияет на ее глобального тезку.
Отлично. Все это хорошо. А вот что тогда делать, если нам зачем-то нужно обратится к этой самой глобальной одноименной переменной.
Для этого есть специальный оператор - ::. С его помощью можно запросто обратится к глобальной области. Как им пользоваться проиллюстрировано в примере ниже:
Code
#include <iostream>
using namespace std;
int s=10;
void main()
{
setlocale(0,"");
int s=30;
cout << "Локальная s =" << s;
cout << "\nГлобальная s =" << ::s; // Вот здесь вот оно, это двойное двоеточие
cin.get();
}
Все, если вы внимательно читали и рассматривали примеры, то должны все понять. Теперь можно вернутся к функциям, и поговорить о том, зачем же нужно их объявление.
Допустим где то в программе, глубоко в областях видимости, хотя это и не важно, у нас есть две функции, использующие для работы друг друга:
Code
void a()
{
b();
}
...
void b()
{
a();
}
Если объявления нет, то как же первая функция узнает о существовании второй?
Вот такой вариант не пройдет:
Code
void b()
{
a();
}
...
void a()
{
b();
}
...
void b()
{
a();
}
Компилятор не допустит существования двух функций с одинаковыми именами. Да и не эффективно это, ведь функция может содержать несколько сотен строк кода. Поэтому, дабы избежать подобных недоразумений, и используется предварительное объявление:
Code
void b();
void a()
{
b();
}
...
void b()
{
a();
}
Проблемы области видимости.
А теперь поговорим о некоторых проблемах для локальных областей видимости. Есть у них один недостаток. Объявленная внутри локальной области переменная существует до тех пор, пока эта область активна. Рассмотрим следующий пример: Code
int* func()
{
int* pi;
int i=55;
pi = &i;
return pi;
}
void main()
{
int* pС;
pС = func();
} Сейчас нам необходимо вспомнить об указателях. Функции способны работать с ними так же, как и с любым другим типом данных. В приведенном примере func()
возвращает указатель на переменную i. Вот только сама переменная, по завершении работы функции, перестает существовать. В результате наш указатель указывает на все, что угодно, то есть по старому адресу, только не на существовавшую ранее переменную, а ее значение (55) окажется потерянным.
Хуже всего то, что компилятор никак не сможет помочь вам избежать таких вот ситуаций. Тут уж все в руках программиста. На этом с видимостью завязываем, и вновь возвращаемся непосредственно к функциям. Ведь узнать нам придется еще очень много.
Windmill 2
WindMill 2D Game Engine
|
|
|
| |
| nilrem | Дата: Суббота, 23 Января 2010, 16:47 | Сообщение # 15 |
|
Просветленный разум
Сейчас нет на сайте
| Урок 3. Обширный функционал
Вообще-то, уже можно было бы приступить к написанию игры. Для использования функций вы знаете все что нужно. Но все же, пока вы серьезно настроены на учебу, я расскажу вам о функциях поподробнее. Я расскажу вам много интересного.
Если же вам невтерпеж, можете сразу переходить к шестому уроку. Вот только в процессе вам все равно придется возвращатся, и перечитывать пропущенное.
Перегрузка функций
Идя по свежим следам, вновь вернемся к именам. Именам функций.
Имя, которое используем мы и имя, которым функция представлена в программе, различны. В отличии от нас, программа также учитывает количество и тип аргументов а также тип возвращаемого значения. Все это вместе называют полным именем функции, ее сигнатурой.
Пример:
Code
int func();
char func(); // ошибка
int func(int);
int func(char);
char func(int,int);
char func(int,float);
Все это разные функции.
Возможность создавать функции с одинаковыми именами называется перегрузкой функций.
И обратите внимание на вторую строку, возле которой приписано "ошибка". От первой она отличается возвращаемым значением. Но на этапе компиляции компилятор не сможет предугадать, какой тип данных будет возвращен, и какую же из перегруженных функций нужно использовать. Поэтому такая перегрузка недопустима и порождает ошибку.
Может возникнуть вопрос, зачем же эта перегрузка нужна. Зачем сознательно вносить такую путаницу в программу. Оказывается для того, чтобы эти самые программы упростить. Понять это поможет следующий пример:
Code
int sum(int a, int b)
{
return a+b;
}
float sum(float a, float b)
{
return a+b;
}
void main()
{
cout<<sum(10,20);
cout<<sum(10.5,20.7);
}
Здесь мы видим перегруженную функцию sum(). Альтернатива это создать функции с разными именами и все время мучится, вызывая правильную для конкретного типа данных. А так компилятор сам подберет нужную, сравнив передаваемые ей типы.
Необходимо отметить, что указанный выше пример работать в Microsoft Visual Studio 2008 не будет. Компиляция завершится следующей ошибкой:
error C2668: sum: неоднозначный вызов перегруженной функции
Поскольку компилятор сам неплохо умеет преобразовывать типы, новые стандарты требуют, чтобы во избежание таких вот ситуаций, программист явно указывал тип данных.
Вот так:
Code
cout<<sum(10.5f,20.7f);
или так:
Code
cout<<sum((float)10.5,(float)20.7);
Значение аргументов по умолчанию.
И еще немного об именах.
В С++ есть возможность присваивать используемым в функциях аргументам значение по умолчанию. Делается это очень просто. Достаточно выполнить присваивание в момент объявления функции:
Здесь аргументу, представленному переменной int i, по умолчанию присвоено 50. Оно будет использоваться, если при вызове не передавать функции никакого значения.
Пример:
Code
#include <iostream>
using namespace std;
void func(int i=50); // обьявление с заданием аргумента по умолчанию
void main()
{
func(); // первый вызов
func(111); // второй вызов
cin.get();
}
void func(int i)
{
cout<<i<<"\n";
}
Здесь при первом вызове функции не передается никакое значение, поэтому используется значение по умолчанию. При втором вызове используется 111.
Конечно же у функции может быть больше одного аргумента.
Code
void func(int arg1, int arg2, int arg3);
Присвоить значение по умолчанию аргументу arg2, можно только в том случае, если значение по умолчанию уже есть у arg3.
Так делать нельзя:
Code
void func(int arg1, int arg2 = 125, int arg3);
Можно только так:
Code
void func(int arg1, int arg2 = 125, int arg3 = 0);
Если объявление функции не используется, то аргументы по умолчанию задаются в ее реализации:
Code
#include <iostream>
using namespace std;
void func(int i=50) // задание аргумента по умолчанию
{
cout<<i<<"\n";
}
void main()
{
func(); // первый вызов
func(111); // второй вызов
cin.get();
}
Встраиваемые функции
Использование функций имеет один маленький недостаток. На вызов функции тратится некоторое время. Происходит это потому, что под код функции резервируется отдельное место в памяти. По ходу выполнения программы, при вызове функции программе приходится переходить к этому месту, а затем возвращаться обратно. Естественно что этот переход не происходит мгновенно, и хорошо если она вызывается всего раз, а вот если 100, значит и переходов будет столько же, и потраченного времени в сто раз больше.
Получается что получить большую скорость работы программы можно, вписывая код функции в место вызова. Это еще бы было нормально, если бы функция вызывалась всего пару раз, а вот если опять сотню. Это ж получится такой объем кода, что сам черт в нем не разберется.
Чтобы обойти все эти проблемы, можно использовать оператор inline.
Синтаксис следующий:
Code
inline Тип_возвращаемого_значения имя_функции(список агрументов);
Пример:
Этот оператор заставляет компилятор встраивать код функции в место ее вызова. Как говорится, и волки сыты и овцы целы, то есть и код небольшой и легко читаем, и программа работает быстро.
Но все же есть одно но. Если такая функция вызывается 100 раз, то при компиляцию в программу будет вставлено 100 ее экземпляров. За увеличение скорости придется заплатить увеличением программного кода и занимаем местом в памяти. В результате никакого выигрыша может и не быть. Поэтому нужно руководствоваться следующим правилом: Если функция содержит всего две-три строки кода, то ее можно, и даже нужно, делать встраиваемой. Если же функция большая, да к тому же используется много раз, то делать ее встраиваемой нельзя.
Статические переменные.
Допустим, что нам зачем-то нужно посчитать, сколько раз конкретная функция вызывалась в программе. Первый пришедший на ум способ сделать это – создать отдельную глобальную переменную и в коде функции увеличивать ее на единицу.
Вот так:
Code
#include <iostream>
using namespace std;
int r=0; // глобальная переменная-счетчик
inline int sum(int a, int b)
{
r++; //использование глобальной переменной
return a+b;
}
void main()
{
for(int i =0;i<50;i++)
{
sum(10,20);
}
cout<<r; // результат подсчета
cin.get();
}
Есть у подобного способа один недостаток. Допустим, вы скопировали вашу функцию в другую программу, или вообще дали своему другу. А в этой другой программе, ну или у друга, нет специально объявленной глобальной переменной. Программа работать не будет и хорошо, если вы вспомните почему.
Естественно, способ решить подобную проблему есть. Это оператор - static.
Объявив с его помощью переменную внутри функции
Code
int sum(int a, int b)
{
static int r=0; // статическая переменная-счетчик
r++;
return a+b;
}
мы сделаем ее общей для всех экземпляров этой функции. Переменная создастся при первом вызове функции и будет существовать до конца работы программы.
Указанная ситуация не единственная, где можно использовать статические переменные.
Между прочим таким способом можно решить описанную выше проблему с областью видимости.
Рекурсивные функции
Может быть то, что я сейчас скажу, покажется вам бредом, но знайте, функция способна вызывать сама себя.
Code
int func()
{
func();
}
Называется эта возможность рекурсией. Рекурсия может быть прямая и косвенная.
Прямая – когда функция вызывает сама себя, косвенная – когда функция вызывает другую функцию, которая в свою очередь вызывает первую. Кстати, это уже знакомая ситуация:
Code
void b();
void a()
{
b();
}
...
void b()
{
a();
}
Применяется рекурсия в разных случаях, когда например нужно выполнить ее для какого то значения, а затем эта же функция применяется к полученному результату.
Для рекурсивных функций является обязательным наличие условия, способного прекратить рекурсию.
Небольшое откровение. Я не люблю рекурсию, особенно прямую. Нет такой ситуации, когда бы без нее нельзя было обойтись. К тому же множественный вызов функций, передача аргументов расходуют дополнительное время и память. Но все же есть одно преимущество - использование рекурсии позволяет сделать код более компактным.
Специально приводить пример рекурсии я не буду.
Windmill 2
WindMill 2D Game Engine
|
|
|
| |
| nilrem | Дата: Суббота, 23 Января 2010, 17:18 | Сообщение # 16 |
|
Просветленный разум
Сейчас нет на сайте
| Урок 4. Функции и указатели.
Прежде чем мы займется темой, соответствующей названию урока, я хочу больше рассказать вам об указателях. Речь пойдет об одном из частых способов их использования. А также об их связи с массивами.
Как вы помните, на прошлом уроке мы в общих чертах познакомились с указателями. Настало время расширить эти знания.
Начнем с простого
Массивы и указатели.
Я уже раньше намекал, что имя массива является также и константным указателем на массив, а также на первый его элемент. Убедится в этом можно из следующего примера:
Code
#include <iostream>
using namespace std;
void main()
{
int array[10];
cout<<'\n'<< array; // отображение адреса массива
cout<<'\n'<<&array [0]; // отображение адреса первого элемента
cin.get();
}
Оба напечатанных адреса будут идентичными.
Напомню, что для отображения адреса первого элемента использовался оператор взятия адреса &, ведь первый элемент это число, а не указатель.
Что же нам это дает? Да ничего особенного, если не знать, что к указателям также можно применять операторы инкременты и декременты. При этом адрес изменяется не на единицу, как обычно, а на размер переменной в байтах.
В результате доступ к элементам массива можно выполнять еще одним способом. Его вы видите в примере:
Code
#include <iostream>
using namespace std;
void main()
{
int a[10];
for(int i=0;i<10;i++)
{
a[i]=i;
cout<<a[i]<<' ';
}
for(int i=0;i<10;i++)
{
cout<<*(a++)<<' ';
}
cin.get();
}
Вот только работать этот пример не будет. Ведь а это константный указатель, то есть изменить его нельзя. Чтобы пример заработал необходимо создать указатель обычный и передать ему адрес из константного:
Code
#include <iostream>
using namespace std;
void main()
{
int a[10];
for(int i=0;i<10;i++)
{
a[i]=i;
cout<<a[i]<<' ';
}
cout<<'\n';
int *pa=a;
for(int i=0;i<10;i++)
{
cout<<*(pa++)<<' ';
}
cin.get();
}
Опять напомню что в записи *(pa++) звездочка это оператор разыменования указателя, с помощью которого получаем хранящееся по адресу значение. Скобки здесь используются, чтобы не запутаться с приоритетами операторов.
При доступе к элементам массива с использованием указателя и инкременты(декременты) остерегайтесь выхода за пределы массива.
Code
#include <iostream>
using namespace std;
void main()
{
int a[10];
for(int i=0;i<10;i++)
{
a[i]=i;
cout<<a[i]<<' ';
}
cout<<'\n';
int *pa=a;
for(int i=0;i<11;i++)
{
cout<<*(pa++)<<' ';
}
cin.get();
}
В этом примере происходит доступ к несуществующему 11 элементу(с индексом 10, ведь как вы помните отсчет начинается с 0). В результате программа выдает нам какое-то, непонятно откуда взявшееся число.
Динамическое распределение памяти.
А сейчас настало время познакомится с одним из самых распространенных способов использования указателей.
Когда ваша программа начинает свою работу, операционная система выделяет для нее место в памяти. Называется это место стек. Размер стека не безграничный, поэтому иногда возникает проблема, когда ваши данные, например большой массив, в него попросту не помещаются. Эта проблема получила название – переполнение стека, и приводит к краху работы программы.
Обидно получается. В компьютере вон сколько памяти, а попытка создать парумегабайтный массивчик делает программу неработоспособной. Но выход есть.
Ко всей этой неиспользуемой, находящейся за пределами стека памяти, можно получить доступ. Память эта, кстати, называется динамической(точнее динамически распределяемой), то есть непостоянной, в противовес постоянному стеку.
Для того, чтобы разместить данные в динамической памяти используется указатель и специальный оператор - new.
Работает он очень просто. По запросу программы он резервирует где-то в динамической памяти свободный кусочек, и возвращает его адрес.
Синтаксис оператора следующий:
Code
указатель = new тип_данных;
Пример:
согласно этой записи оператор new выделит в области динамического распределения некий, соответствующий размеру типа данных, объем памяти, и передаст указателю pi его адрес. Как мы помним, размер целочисленного типа данных 4 байта, столько и будет выделено.
В дальнейшем доступ к этой памяти производится через указатель.
Code
#include <iostream>
using namespace std;
void main()
{
int *pi = new int;
*pi=10;
cout<<*pi;
cin.get();
}
Ключевой особенностью использования динамически распределенной памяти является ее независимость от области видимости. Будучи созданной один раз она доступна везде, куда можно передать ее адрес:
Code
#include <iostream>
using namespace std;
int* func()
{
int* pa=new int; // динамическое выделение памяти
*pa=123123;
return pa; // возврат адреса
}
void main()
{
int* pi;
pi=func(); // получение адреса на распределенную память
cout<<*pi;
cin.get();
}
Здесь функция func() возвращает адрес на динамически выделенную память. Теоретически после завершения работы функции все созданные в ней переменные должны быть утрачены. Но это не относится к динамическому распределению памяти. Что и подтверждает строчка cout<<*pi;, печатающая ранее присвоенное в функции и никуда не подевавшееся корректное значение.
Динамическое распределение памяти настолько мощное средство, что даже по завершению программы выделенная в ней память остается недоступной для других программ.(Было это во времена ДОСа и первых Windows, сейчас же операционные системы работают с памятью более грамотно). Так вот, если все время выделять память, рано или поздно она кончится. Поэтому когда память под переменную становится не нужной, ее нужно освободить. Для этих целей используется оператор delete.
Синтаксис следующий:
здесь указатель – это указатель на динамически-распределенную область памяти.
Пример:
Code
#include <iostream>
using namespace std;
int* func()
{
int* pa=new int;
*pa=123123;
delete pa; // освобождение ранее выделенной памяти.
return pa;
}
void main()
{
int* pi;
pi=func();
cout<<*pi;
cin.get();
}
Теперь все отлично, память мы освободили. Вот только программа стала неработоспособной. Ведь освободив память мы уничтожили хранящееся там значение.
Как же тогда быть. Ведь если не использовать delete внутри функции, по ее завершении указатель прекратит свое существование, а значит и освободить память будет невозможно. А вот и нет. При использовании delete это не обязательно должен быть тот самый указатель, но это обязательно должен быть тот самый адрес.
Code
#include <iostream>
using namespace std;
int* func()
{
int* pa=new int;
*pa=123123;
return pa;
}
void main()
{
int* pi;
pi=func();
cout<<*pi;
delete pi; // освобождение ранее выделенной памяти.
cout<<*pi;
cin.get();
}
Предупреждаю сразу – это был плохой пример. Посмотрите его и забудьте. Если где-то в функции выделяется память, то она в этой функции и должна освобождаться. Лучше по новому выделить в main память и передать туда значение, а не разбрасываться вот так вот памятью, а то в конце концов можно окончательно запутаться, и превратить свой код в кучу мусора. Тем не менее таким способом пользуются довольно часто, особо отмечая, что потом память нужно освобождать, например создавая для этого специальные функции и указывая в документации, что их вызов по окончании работы обязателен.
Иногда программист забывает где-то освободить память, и если этот код выполняется неоднократно, можно выделить довольно много памяти в никуда. Такую ситуацию называю утечкой памяти, и это одна из довольно распространенных ошибок, которые в будущем попортят вам нервы.
С выделением памяти под обычные переменные разобрались, теперь рассмотрим как это делается с массивами.
Code
указатель = new тип_данных[размер массива];
В принципе разница небольшая. Необходимо всего лишь указать после типа данных размер массива. Для того чтобы освободить выделенную таким образом память используется следующая запись.
Code
delete [] указатель;
здесь квадратные скобки указывают, что удаляется именно массив. Указывать размер при этом не нужно.
Что то мой разговор об указателях затягивается, пора возвращаться к функциям.
Параметры-адреса
Давайте рассмотрим такой простой пример:
Code
#include <iostream>
using namespace std;
void print(int a)
{
a = 32;
cout<<a<<'\n';
}
void main()
{
int i=10;
print(i);
cout<<i<<'\n';
cin.get();
}
Здесь у нас есть функция print, которой передается переменная i. Внутри функции этой переменной присваивается новое значение. Но потом, после функции оказывается что значение переменной i осталось неизменным. То есть изменить значение переменной, которая передавалась функции как аргумент, нельзя.
Так происходит потому, что функции на самом деле передается не оригинальная переменная, а всего лишь хранящееся в ней значение. Поэтому такой способ передачи называют передачей по значению. Любые манипуляции с этим значением внутри функции оригинальную переменную не затрагивают.
Получается, что бы не делала функция результат ее работы за пределы функции не выйдет. В таком случае зачем они вообще нужны. Ах, да. Функция же может возвращать значение. Вот только всего одно. А если нам нужно больше?
Тут на помощь опять приходят указатели. Функция работает с указателями так же, как и с обычными переменными, то есть передает их значение. А что у нас хранится в указателе? Правильно, адрес ячейки памяти, в которой хранится некое значение. А значит мы можем в полной мере воздействовать на это значение. Это проиллюстрировано следующим примером:
Code
#include <iostream>
using namespace std;
void print(int* a)
{
*a = 32;
cout<<*a<<'\n';
}
void main()
{
int i=10;
int *pi = &i;
print(pi);
cout<<i<<'\n';
cin.get();
}
Здесь в функции объявляется переменная i, которой присваивается число 10. Затем эта переменная передается функции print. Причем передается не сама переменная, а указатель на нее, как того требует прототип функции:
аргументом функции является указатель, то есть попросту говоря адрес. Внутри функции с помощью оператора разыменования * по адресу присваивается новое значение. По завершении работы функции оказывается, что теперь значение переменной i изменилось, и равно тому, что было присвоено в функции. То есть нам удалось изменить значение переданной функции переменной. Что и требовалось. Вот такие вот полезные указатели. Такой способ передачи аргументов называется передачей по указателю.
Добавлю, что запись
Code
int *pi = &i;
print(pi);
можно сократить так:
здесь адрес берется непосредственно при передаче переменной в функцию.
Кроме передачи по значению и передачи по указателю есть еще и третий способ, называемый передача аргументов по ссылке.
Он не требует от программиста непосредственной работы с указателями, хотя тоже работает с адресами переменных. Но вся эта работа скрыта от программиста.
Вот предыдущий пример, измененный так, чтобы продемонстрировать передачу по ссылке.
Code
#include <iostream>
using namespace std;
void print(int& a)
{
a = 32;
cout<<a<<'\n';
}
void main()
{
int i=10;
print(i);
cout<<i<<'\n';
cin.get();
}
Здесь ключевую роль играет запись аргументов в объявлении функции.
int& a означает что будет производится передача по ссылке(можно сказать что переменная а это новый тип данных, который называется ссылка, и является синонимом адреса). В коде примера нет ни одного указателя. Но функция print(i)получает не значение переменной, а ее адрес, и записывает 32 по этому адресу. То есть результат тот же, что и при использовании указателей.
По-моему, намного проще.
Windmill 2
WindMill 2D Game Engine
|
|
|
| |
| nilrem | Дата: Суббота, 23 Января 2010, 17:37 | Сообщение # 17 |
|
Просветленный разум
Сейчас нет на сайте
| Для обсуждения, вопросов и замечаний создана отдельная тема. http://gcup.ru/forum/7-1739-1
Windmill 2
WindMill 2D Game Engine
|
|
|
| |
|








